
In 2025, language-driven intelligence is no longer a niche capability—it underpins global communication, business automation, and user experiences across industries. Natural Language Processing (NLP) has matured from academic curiosity into an essential toolkit that helps machines understand, reason with, and generate human language. The power of NLP lies not only in translating words but in inferring intent, context, and nuance from vast textual data, enabling machines to assist, augment, and sometimes collaborate with humans in meaningful ways. This article explores the core foundations of NLP, its diverse applications, the vibrant ecosystem of platforms and players, the pressing ethical questions, and a practical path to building real-world NLP solutions in 2025. By examining theory, technology, and practice in parallel, readers will gain a holistic understanding of how NLP shapes products, services, and everyday interactions, and how to navigate the opportunities and challenges that come with deploying language-enabled systems at scale.
En bref:
- NLP combines linguistics, computer science, and statistics to interpret and generate human language.
- Modern NLP hinges on transformer architectures, large language models, and efficient training pipelines that scale with data and compute.
- Applications span information retrieval, dialogue systems, translation, sentiment analysis, and more with measurable business impact.
- Ethical and governance considerations are integral to design, deployment, and evaluation, especially around bias, privacy, and accountability.
- A thriving ecosystem includes Google, Microsoft, OpenAI, AWS, IBM Watson, Apple, Meta, Baidu, NVIDIA, SAP, and many open-source communities.
Foundations of Natural Language Processing in 2025: Theory, Models, and Core Technologies
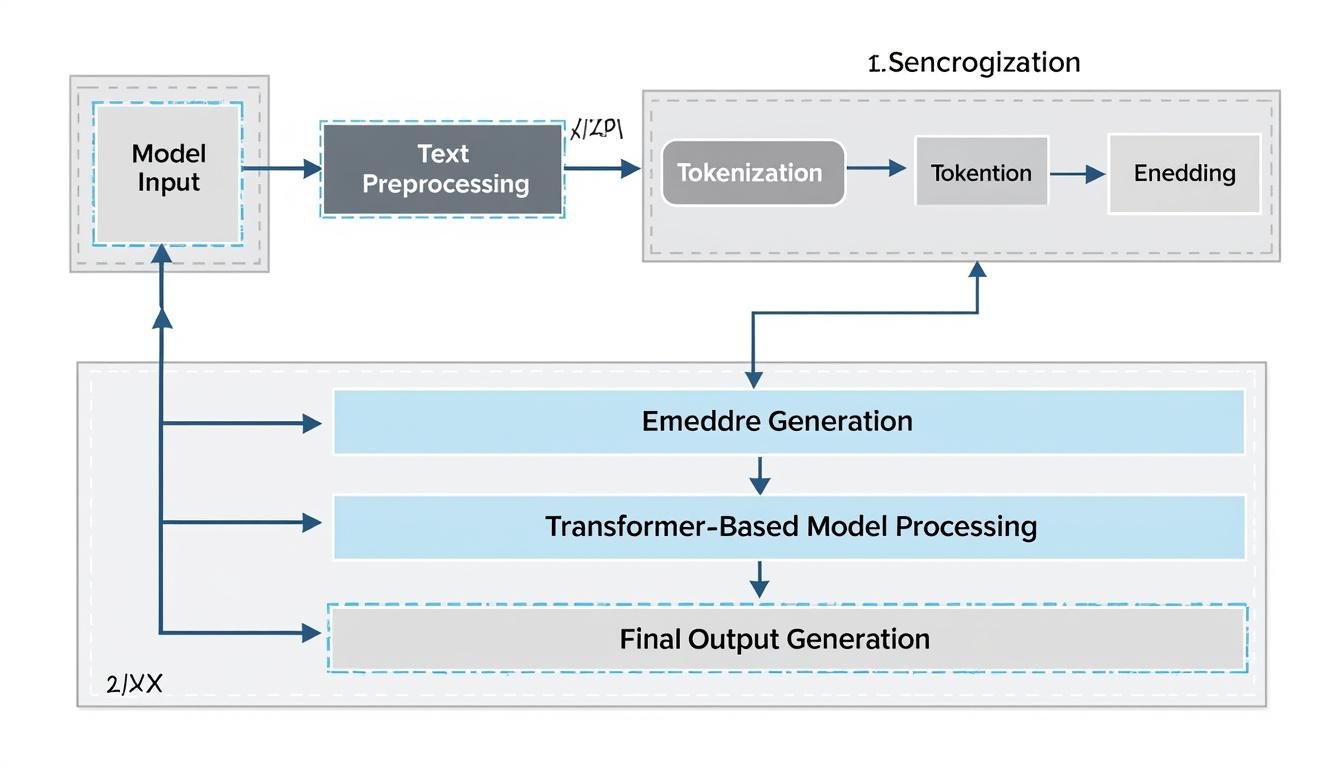
Natural Language Processing rests at the intersection of linguistic insight and computational prowess. At its core, NLP aims to unravel the structure of language—how words form phrases, how clauses convey meaning, and how context shifts interpretation. This requires a blend of linguistic theories and statistical methods that let machines handle ambiguity, variability, and cultural nuance. In 2025, the field has evolved beyond symbolic rules and shallow heuristics toward data-driven, context-aware approaches that can generalize across domains and languages. To appreciate this evolution, it helps to decompose NLP into three interconnected layers: representation, modeling, and interaction.
The representation layer translates raw text into machine-interpretable formats. Traditional techniques relied on handcrafted features and bag-of-words representations, while contemporary approaches use dense embeddings, contextualized vectors, and multimodal signals. The move toward contextual embeddings—where word meaning shifts with surrounding text—marked a turning point, enabling models to capture syntax, semantics, and pragmatic cues in one unified representation. In practice, this means a model can distinguish between “bank” as a financial institution and a riverbank based on the sentence.
The modeling layer encompasses algorithms and architectures that learn from data. Transformers have become the backbone of most NLP systems due to their ability to capture long-range dependencies and parallelize training. Large language models (LLMs) exemplify this trend, offering capabilities ranging from text completion to code generation and reasoning. Yet deploying these models responsibly requires attention to efficiency, adaptability, and safety—topics that researchers and practitioners continually explore. If you’re curious about the practical underpinnings, consider reading a comprehensive guide to data analysis, which explains how extraction, cleansing, and transformation feed model training. Data analysis foundations provide a blueprint for turning messy data into reliable signals.
The interaction layer centers on how users, systems, and contexts meet NLP capabilities. Dialogue agents, question-answering systems, and search engines must interpret user intent, manage conversational state, and respond in a natural, concise manner. The 2025 landscape emphasizes interactive and multi-turn conversations, multimodal inputs (text, speech, images), and user-centric safety nets. For a broader view on how humans and machines interact, explore resources on human-computer interaction and how to bridge user needs with technical solutions. A practical read on the topic offers a historical and contemporary perspective on interface design and cognitive load. HCI perspectives in NLP.
| Aspect | Definition | Key Example | Notes |
|---|---|---|---|
| Tokenization | Splitting text into meaningful units | Words, subwords, or characters depending on language | Crucial for downstream models; affects performance on morphologically rich languages |
| Embeddings | Dense vector representations of text | WordPiece, BPE, or sentence embeddings | Capture semantic similarity; contextual variants require dynamic embeddings |
| Modeling | Algorithms that learn from data to map input to output | Transformers, sequence-to-sequence models | Scale and pretraining objectives shape capabilities and biases |
| Evaluation | Measured performance on standardized tasks | BLEU, ROUGE, F1, human evaluation | Metrics must reflect real-world usefulness and fairness |
| Deployment | Operationalizing models for users | APIs, on-device inference, real-time dialogue | Latency, privacy, and monitoring are critical considerations |
NLP research and practice converge on a few practical principles: prioritizing data quality and representativeness, designing robust evaluation that captures user impact, and building systems that can explain and audit their decisions. The inclusion of multilingual capabilities and domain adaptation remains central to broad applicability. In particular, across 2025 deployments, organizations increasingly seek models that can be fine-tuned efficiently to new domains without compromising safety or introducing bias. This shift has spurred a surge of work on reproducibility, data governance, and transparent reporting of model limitations. For an overview of how data analysis informs model performance, the linked guide on data analysis provides practical steps for preparing datasets that support reliable NLP outcomes. Data analysis best practices are a valuable companion to every NLP project.
To further enrich the practical understanding of NLP foundations, consider how industry actors leverage these technologies. Google, Microsoft, OpenAI, and AWS lead in scalable infrastructure; IBM Watson and SAP contribute domain-specific solutions; Apple, Meta, and Baidu push multilingual and consumer-grade experiences; NVIDIA accelerates training and inference, while a broad network of open-source communities accelerates innovation. The interplay between these players shapes accessible tooling, model availability, and standards that affect researchers and developers alike. In this context, the following sections explore real-world applications, ecosystems, and governance challenges that enterprises face when bringing NLP from concept to customer value.
As a first step toward practical mastery, a short overview video can illuminate concepts such as attention mechanisms, transformer blocks, and the idea of context windows. The next sections dive into concrete applications and architectural choices that teams can tailor to their needs.
Applications and Impact of NLP in 2025: Use Cases, Case Studies, and ROI
The practical value of NLP emerges when organizations translate language understanding into tangible outcomes. In 2025, NLP powers smarter search, faster support, higher-quality translations, and more insightful data analysis. The ROI of NLP is not merely in automation; it also manifests as improved customer experience, faster decision cycles, and better risk management. Businesses that implement NLP thoughtfully align it with workflows that benefit from language understanding—whether that means triaging customer inquiries, extracting structured insights from unstructured notes, or generating coherent summaries of long documents. Across industries, leaders are investing in end-to-end pipelines that move from raw text to actionable signals, with governance layers ensuring safety, fairness, and compliance. For a broader perspective on data-driven insights, readers can explore the comprehensive guide to data analysis as a foundation for building reliable NLP systems. Data analysis foundations help ensure signals are trustworthy before models are trained.
Key use cases span several core domains, each with distinct requirements and success metrics. Below is a practical snapshot of representative applications, accompanied by real-world considerations, typical datasets, and example outcomes. The table presents an concise synthesis of how NLP translates to business value, while the bullet lists highlight considerations and trade-offs that practitioners should weigh when designing a solution.
| Domain | NLP Application | Typical Data | Expected Value |
|---|---|---|---|
| Customer Support | Dialogue systems, sentiment analysis, and intent classification | Chats, emails, support tickets | Reduced response time, higher resolution on first contact |
| Information Retrieval | Semantic search, document ranking, question answering | Knowledge bases, manuals, intranets | Faster access to relevant information and improved accuracy |
| Healthcare | Clinical note annotation, risk stratification, medical translation | EMRs, lab reports, patient notes | Improved documentation quality and decision support |
| Finance | News analytics, sentiment-driven signals, document summarization | Market reports, earnings transcripts | Timely insights and risk-aware decision-making |
| Localization | Machine translation with post-editing | Product interfaces, user manuals | Faster time-to-market and consistent terminology |
- Prioritize multilingual coverage and domain adaptation to maximize reach.
- Balance generative capabilities with strict governance to avoid harmful outputs.
- Measure not only accuracy but user satisfaction and task success rates.
- Invest in data privacy and model transparency to earn user trust.
For a broader exploration of data-driven NLP applications and case studies, see the following resources embedded in the broader ecosystem: Top AI-powered apps for 2025, Healthcare in a $4T landscape, and Exploring creative NLP in outpainting. These materials illustrate how NLP techniques translate into practical workflows and measurable improvements across sectors.
Following that video, we examine how enterprises implement NLP in production, balancing speed, accuracy, and safety. A typical deployment involves data collection, preprocessing, model selection or training, evaluation, and continuous monitoring—each stage with its own metrics and governance controls. The next section delves into the broader ecosystem of platforms and players that empower these deployments, from cloud providers to specialized vendors and open-source communities.
NLP Ecosystem: Major Platforms, Vendors, and Open-Source Communities
The NLP ecosystem in 2025 is a rich tapestry of cloud platforms, research hubs, and commercial solutions. Giants like Google, Microsoft, OpenAI, and AWS provide scalable infrastructure, prebuilt models, and tooling that accelerate time-to-value. IBM Watson and SAP offer domain-focused NLP capabilities that integrate with enterprise software ecosystems. Consumer-facing tech companies—Apple, Meta, and Baidu—drive multilingual performance and user-centric experiences. NVIDIA underpins the computational backbone with accelerators that shorten training times and enable real-time inference. The landscape also thrives through vibrant open-source communities that democratize access to cutting-edge techniques and foster collaboration. This ecosystem is not just about technology; it shapes standards, interoperability, and the pace at which organizations can experiment and deploy responsibly.
Key platform categories and roles:
- Cloud AI platforms enable scalable training, hosting, and inference for NLP models, with features for monitoring, security, and compliance.
- Commercial NLP suites offer end-to-end capabilities—dialogue management, sentiment, translation, and analytics—often integrated with business software.
- Open-source libraries and communities provide building blocks, reference implementations, and rapid experimentation paths.
- Hardware accelerators and optimized runtimes reduce latency and energy use in production systems.
- Research labs and corporate R&D push the boundaries of model architectures and safety mechanisms.
In practice, organizations choose a mix of tools to align with their needs, from Google and Microsoft cloud NLP services to OpenAI-backed models and AWS deployment options. Enterprise buyers often evaluate on-premises versus cloud-hosted options, governance features, and the ability to plug NLP capabilities into existing data pipelines and analytics platforms. A well-rounded strategy also brings in IBM Watson for industry-specific capabilities, SAP for ERP-related NLP tasks, and NVIDIA hardware for heavy workloads. For practical exploration of data analysis in enterprise contexts, the linked article on data analysis provides a blueprint for turning raw data into trustworthy NLP signals. Data analysis blueprint.
To ground this discussion in real-world references, consider the ecosystem map and case studies at major vendor sites and research consortia. Industry practitioners frequently compare the features, pricing models, and governance controls of cloud-native NLP platforms. The result is a pragmatic mix of off-the-shelf capabilities and bespoke models that address regulatory and ethical requirements. For deeper context on the practical implications of integrating NLP with business processes, you can explore the broader discussion in the data-analysis guide and related case studies mentioned above.
Ethics, Privacy, and Governance in NLP Systems
As NLP systems permeate customer interfaces, internal tools, and decision-support pipelines, governance becomes as important as performance. The ethical dimension of NLP encompasses bias mitigation, fairness in decision-making, user consent, and transparency about how language models operate. In 2025, organizations are increasingly implementing governance frameworks that address model provenance, data lineage, and risk assessment. The goal is to prevent amplification of social biases, respect user privacy, and ensure that automated language outputs can be explained, audited, and corrected when necessary. This requires a combination of technical safeguards—such as bias auditing, differential privacy, prompt constraints, and robust logging—and organizational practices, including governance committees, ethics review boards, and clear internal policies on data usage and model deployment.
Key ethical practices include:
- Bias and fairness audits across languages and domains, with remediation plans for identified gaps.
- Privacy-preserving techniques that minimize exposure of sensitive information in training data and outputs.
- Transparency about model capabilities, limitations, and the potential for unintended consequences.
- Human-in-the-loop controls for high-stakes use cases where safety is paramount.
- Audit trails and explainability tools that help users and regulators understand decisions.
Organizations can leverage a variety of references and frameworks to structure their governance efforts. For instance, mapping your NLP initiatives against industry standards and legal requirements helps ensure compliance in different markets. Engaging with academic and practitioner communities—through conferences, open-source collaborations, and industry partnerships—facilitates ongoing learning and alignment with evolving norms. To explore practical data governance and ethical considerations further, the data analysis guide and related resources provide actionable guidance for responsible NLP practice. Data governance in NLP offers structured approaches to risk assessment and accountability.
Another dimension is the user experience: making NLP outputs understandable and controllable for end-users. This includes designing interfaces that present confidence estimates, limitations, and options for human override. The human-centered approach reduces the risk of overreliance on automated language capabilities and supports sustainable adoption across teams and customers. The journey toward responsible NLP is ongoing and iterative, demanding continuous evaluation, user feedback, and updates to governance practices as models evolve and new risks emerge.
Two more perspectives underscore the broader landscape: first, cross-language fairness requires attention to linguistic and cultural differences that affect model behavior; second, interoperability and data-sharing agreements must align with privacy laws and corporate policies. For a broader perspective on how to navigate these issues, the linked resources on data analysis and related case studies offer practical insights, while the linked data-analysis guide helps frame extraction, transformation, and governance steps that feed ethical NLP practice. AI-powered apps for 2025 and Healthcare in a $4T system illustrate how governance shapes clear, responsible outcomes in diverse contexts.
What are the biggest ethical concerns in NLP today?
Bias, fairness, privacy, explainability, and accountability are central concerns as NLP systems become more capable and pervasive. Responsible practice requires ongoing audits, transparent reporting, and human oversight for high-stakes tasks.
How can organizations mitigate bias in NLP models?
Approaches include diverse training data, bias audits, calibration across languages, multi-stakeholder review, and post-training mitigation techniques. Combining technical measures with governance processes is essential.
What is the best way to measure NLP impact in business?
Define task-specific metrics (accuracy, F1, BLEU, ROUGE) alongside user-centric metrics (satisfaction, task completion rate, time savings) and perform causal analyses to assess ROI.
Which platforms are most relevant for enterprise NLP in 2025?
Key platforms include Google, Microsoft, AWS, IBM Watson, SAP, and OpenAI-powered offerings, complemented by Apple, Meta, Baidu, and NVIDIA ecosystems, plus strong open-source contributions.
How can I start an NLP project in a regulated industry?
Begin with a clear problem statement, gather representative data, apply bias and privacy safeguards, assemble governance, and use pilot studies with human-in-the-loop evaluation before scaling.
Building and Deploying NLP Solutions: Practical Roadmap for 2025
Turning NLP concepts into products requires a disciplined, iterative approach that combines data engineering, model selection, and deployment discipline. The practical roadmap below is designed to help teams move from an abstract idea to a trusted, scalable NLP solution. It emphasizes alignment with business goals, risk management, and an architecture that supports measurement, feedback, and governance. In 2025, success hinges on the ability to start small, demonstrate value quickly, and progressively raise the bar in terms of capability, reliability, and responsibility. The roadmap integrates best practices in data preparation, model selection, evaluation, deployment, monitoring, and continuous improvement, with links to relevant resources for deeper learning and concrete templates.
- Problem framing: define the user problem, success metrics, and constraints. Create a narrative that connects NLP capability to business outcomes and customer experience.
- Data strategy: assemble, clean, and annotate data; assess coverage across languages and domains; establish data governance and privacy boundaries. See the data analysis guide for practical steps.
- Model choice and customization: select pretrained models suitable for the task, consider fine-tuning versus prompt-based approaches, and plan for domain adaptation. Evaluate trade-offs between latency, cost, and accuracy.
- Evaluation framework: establish task-specific metrics, conduct human-in-the-loop testing for edge cases, and validate fairness across populations and languages.
- Deployment plan: decide on cloud versus on-prem, implement monitoring for drift and safety, and integrate with existing systems and workflows. Build robust API interfaces with clear SLAs.
- Governance and ethics: implement bias audits, privacy controls, model cards, and explainability dashboards to support accountability and user trust.
- Scale and maintenance: design for incremental improvement, versioning, data lineage, and rollback strategies to minimize risk during updates.
The journey from data to deployment is iterative and cross-disciplinary. For teams starting with a data-analysis mindset, the earlier linked guide on data analysis offers a foundational perspective on how to manage data quality and signal extraction. Additionally, engaging with industry resources that discuss data strategies—such as the AI-powered apps and enterprise case studies—helps translate technical choices into tangible business outcomes. If you’re exploring practical case studies or want to compare operators and tooling, consider reading the surrounding articles and vendor resources linked throughout this article. These references illustrate how companies across sectors are applying NLP to improve products, services, and efficiency, while maintaining governance and user trust.
The deployment path also emphasizes continuous learning: gather user feedback, monitor system behavior in production, and re-train or adjust models as needed. In 2025, the pace of innovation is rapid, but responsible execution remains essential. The practical insights offered here aim to equip teams with a durable framework to navigate the evolving NLP landscape—balancing speed, quality, and ethics as they transform language into value. If you want to explore more about the foundations and applications of linear algebra, capsule networks, or human-computer interaction, follow the recommended readings and data-analysis resources linked earlier in this article to deepen your understanding and practical capabilities.
To summarize, the NLP journey in 2025 blends theory with practice, powered by a dynamic ecosystem of platforms and people. The choices you make about data preparation, model selection, governance, and deployment will determine not only technical performance but also user trust and business impact. Remember to keep the conversation open with stakeholders, document decisions transparently, and measure outcomes in terms of user success and organizational value. The path is challenging but navigable with a clear roadmap, careful governance, and a commitment to responsible innovation.
For further reading and practical templates, consult the following resources: Exploring the foundations and applications of linear algebra, Capsule networks in neural architectures, and Human-computer interaction dynamics. These writings offer deeper mathematical, architectural, and interface perspectives that enrich the NLP deployment journey.
Moreover, the practical roadmap integrates insights from major players in the NLP field, including Google, Microsoft, OpenAI, and Amazon Web Services, as well as IBM Watson, Apple, Meta, Baidu, NVIDIA, and SAP. Each contributor brings unique strengths—from scalable infrastructure and pretrained models to domain-specific software suites and hardware acceleration. This collaborative landscape accelerates experimentation and expansion, enabling teams to design language-enabled solutions that are not only powerful but also ethical, reliable, and aligned with user needs. As you embark on this journey, remember that success lies in combining thoughtful data practices, rigorous evaluation, responsible governance, and a clear value proposition for end users. The future of NLP depends on the quality of decisions you make today.


