
En bref
- LSTM est une catégorie de réseaux de neurones récurrents conçue pour capter les dépendances de longue durée dans les données séquentielles.
- Introduites en 1997, les portes d’entrée, d’oubli et de sortie permettent de réguler le flux d’informations vers l’état caché et l’état cellule, résolvant le problème du gradient qui disparaît.
- En 2025, les LSTM coexistent avec les Transformers et servent de référence dans des scénarios nécessitant une faible latence et une robustesse face à des données limitées, tout en s’intégrant parfaitement à des stacks comme TensorFlow, Keras, PyTorch et Hugging Face.
- Les domaines d’application restent variés: modélisation du langage, reconnaissance vocale, traduction et prévision de séries temporelles, avec des implémentations soutenues par Google AI, OpenAI, DeepMind, Microsoft Azure AI, IBM Watson et AWS Machine Learning.
Comprendre les LSTM, c’est entrer dans le cœur des mécanismes qui donnent à ces réseaux la capacité de « se souvenir » au-delà de quelques pas. Les architectures LSTM introduisent un chemin d’information qui traverse les étapes de traitement, soutenu par un état cellule robuste et des mécanismes de contrôle appelés portes. Avec leurs origines dans les années 1990 et leur raffinement continu, les LSTM restent une référence pragmatique pour les tâches où les dépendances à long terme et la stabilité du gradient importent le plus. En 2025, ils s’insèrent dans des chaînes modernes de développement qui tirent parti de cadres comme TensorFlow, Keras et PyTorch, tout en étant complémentaires à l’approche Transformer dans des scénarios hybrides ou à faible disponibilité de données.
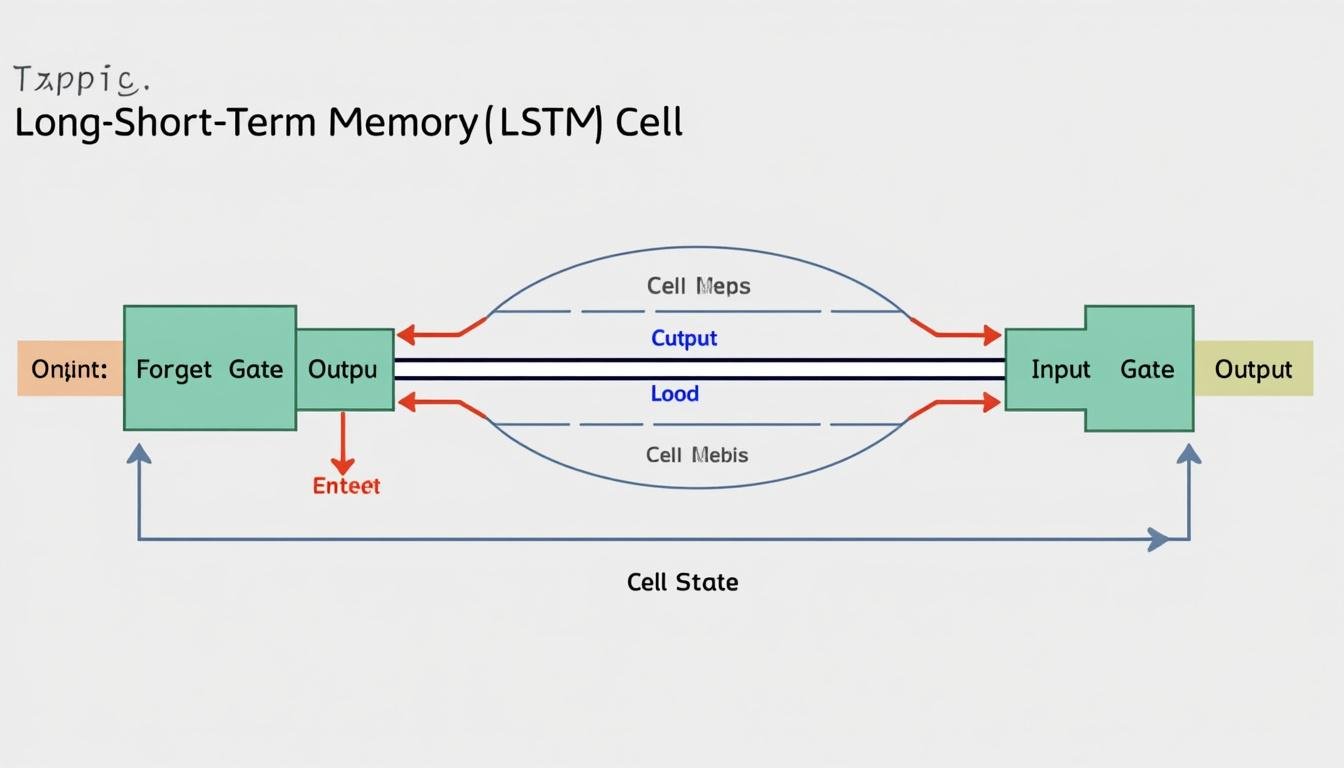
Understanding Long Short-Term Memory: Fondements et Gates dans les LSTM (2025)
Gates et mécanismes clés dans les LSTM
Les LSTM s’appuient sur trois portes apprises qui contrôlent le flux d’informations à travers le réseau à chaque étape temporelle. La porte d’oubli décide quelles informations laisser passer, la porte d’entrée détermine quelles nouvelles valeurs seront ajoutées à l’état, et la porte de sortie influence l’information transmise à l’extérieur du bloc LSTM. Ensemble, elles permettent de maintenir ou de modifier l’état cellule en fonction du contexte actuel et des informations passées.
- Forget gate: filtre les informations inutiles pour éviter une surcharge mémoire.
- Input gate: décide quelles valeurs candidat seront intégrées à l’état.
- Output gate: détermine quelle partie de l’état est exposée à l’étape suivante.
Cette orchestration rend les LSTM particulièrement adaptés à des tâches comme la modélisation du langage et la reconnaissance vocale, où les dépendances peuvent s’étendre sur des dizaines ou centaines d’étapes.
| Portes | Rôle | Effet typique |
|---|---|---|
| Forget | Économiser ou oublier des informations passées | Réduction du bruit et prévention du débordement mémoire |
| Input | Décider des valeurs candidates à ajouter | Intégration sélective d’informations pertinentes |
| Output | Contrôler ce qui est transmis à l’étape suivante | Extraction d’informations utiles pour la prédiction |
Pour approfondir les concepts, vous pouvez consulter des ressources sur les bases de l’IA et le vocabulaire associée, par exemple:
Concepts clés de l’IA,
Terminologie de l’IA, et
Vocabulaire de l’IA.
Les portes s’appuient sur des paramètres apprendus pendant l’entraînement, et leur interaction détermine le flux d’information à travers le temps. Dans les cadres modernes, ces mécanismes sont couramment implémentés avec des architectures comme TensorFlow et PyTorch, et soutenus par des bibliothèques spécialisées telles que Keras et Hugging Face.
État cellule et mémoire à long terme
L’élément central d’un LSTM est l’état cellule, qui agit comme une mémoire qui traverse l’ensemble de la séquence. Cet état peut être renforcé ou effacé par les portes, ce qui permet de préserver des informations essentielles sur une longue période tout en filtrant le bruit. Le flux du gradient à travers l’état cellule est conçu pour rester stable, même lorsque les séquences deviennent longues.
- État cellule: mémoire durable qui porte l’information au fil du temps
- Équilibre entre oubli et ajout: la dynamique des portes ajuste le contenu
- Influence sur les tâches séquentielles: traduction, transcription et prévision
| Rôle | Impact sur la prédiction | |
|---|---|---|
| Cell state | Conserve les informations pertinentes | Améliore la cohérence sur les dépendances longues |
| Hidden state | Représente la sortie à l’instant t | Guide les couches suivantes et la prédiction |
| Gradient flow | Stabilité lors de l’entraînement | Réduit l’erreur vanishing |
Des ressources complémentaires sur les RNN et les architectures récurrentes offrent des perspectives utiles pour comprendre leur évolution et leur place dans les systèmes d’IA modernes. Consultez par exemple les pages suivantes:
Réseaux neuronaux récurrents,
Explorer les réseaux neuronaux, et
L’essor de l’IA et ses implications.
Les LSTM restent un choix pertinent dans des contextes industriels où la robustesse et l’interprétabilité locale priment, tout en s’intégrant dans des chaînes d’ingénierie modernes avec TensorFlow, Keras, PyTorch et les écosystèmes associées.
Implémentation et cadres modernes pour LSTM en 2025
Choix des frameworks et pratiques de développement
Dans les environnements de production, les LSTM peuvent être implémentés à l’aide de cadres répandus tels que TensorFlow ou PyTorch, avec Keras comme API haut niveau pour accélérer le prototypage. D’autres acteurs majeurs comme Google AI et DeepMind alimentent ces outils, tandis que des plateformes cloud comme Microsoft Azure AI et AWS Machine Learning facilitent l’orchestration et le déploiement. Des solutions d’entreprise comme IBM Watson et Hugging Face enrichissent les possibilités de pré-traitement et de fine-tuning des modèles.
- TensorFlow et Keras pour une intégration rapide et portable
- PyTorch pour le développement itératif et le débogage interactif
- Hugging Face pour les modèles pré-entraînés et les pipelines NLP
- Google AI et DeepMind comme sources d’innovations et d’exemples de référence
- Microsoft Azure AI et AWS Machine Learning pour le déploiement à grande échelle
| Cadre | Langage principal | Avantages | Cas d’usage typiques |
|---|---|---|---|
| TensorFlow | Python | Écosystème riche, déploiement multiplateforme | Production ML, prétraitement et entraînement |
| PyTorch | Python | Dynamiques des graphes, débogage facilité | Prototype rapide, recherche |
| Keras | Python | API simple, intégration avec TF | Prototype et déploiement rapide |
| Hugging Face | Python | Modèles NLP pré-entraînés | Fine-tuning et déploiement NLP |
Pour en savoir plus sur les perspectives et les concepts de l’IA, voici des ressources utiles:
Concepts clés,
Terminologie IA, et
Vocabulaire IA.
- Évaluez les besoins en latency et en mémoire pour choisir entre LSTM et Transformer.
- Choisissez le cadre en fonction de l’écosystème existant et du niveau de complexité souhaité.
- Planifiez le déploiement avec des considérations de coût et de scalabilité sur Google Cloud, AWS ou Azure.
Pour un approfondissement sur les concepts et les jargon de l’IA, consultez ces ressources complémentaires:
Capacités des réseaux neuronaux,
RNN et LSTM.
Applications pratiques des LSTM en 2025 et perspectives
Cas d’usage typiques et scénarios réels
Les LSTM restent des choix solides pour des tâches où il faut mémoriser des informations sur des intervalles de temps prolongés. En 2025, ils sont couramment utilisés dans la modélisation du langage, la reconnaissance vocale et la prévision de séries temporelles sensibles à long terme. Les entreprises s’appuient sur des stacks d’outils variés, allant de TensorFlow et PyTorch à des services cloud gérés par Microsoft Azure AI ou AWS Machine Learning, tout en bénéficiant des avancées en matière de pré-trainement et de fine-tuning via Hugging Face.
- Modélisation du langage et génération de texte
- Reconnaissance vocale et traduction automatique
- Prévision de séries temporelles multivariées
- Analyse des tendances et détection d’anomalies dans les flux de données
| Domaine | Exemple concret | Indicateur de performance |
|---|---|---|
| NLP | Modèles de génération et d’interprétation | Perplexité, BLEU |
| Vocal | Reconnaissance et synthèse | WER, MOS |
| Finance et IoT | Prévision de séries temporelles | MAE, RMSE |
Pour approfondir les concepts et les définitions associées, voir les articles suivants:
Concepts clés de l’IA,
Terminologie IA, et
Jargon IA.
- Évaluez les besoins en latency et en précision pour choisir entre LSTM et Transformer.
- Considérez le coût et l’échelle lors du déploiement sur le cloud (Azure AI, AWS ML).
- Intégrez des pipelines de monitoring pour suivre l’évolution des performances en production.
Ressources complémentaires utiles pour élargir votre compréhension:
Réseaux neuronaux et IA,
Impact et avenir de l’IA.
Qu’est-ce que LSTM et pourquoi a-t-il été développé ?
LSTM est un type de RNN doté de mécanismes de portes et d’un état cellule, ce qui permet de préserver des informations pertinentes sur de longues séquences et de lutter contre la perte d’information lors du passage dans le temps. Créé pour répondre au problème du gradient, il offre une meilleure stabilité lors de l’entraînement sur des dépendances longues.
Comment les portes travaillent-elles exactement dans un LSTM ?
Les trois portes (oubli, entrée et sortie) contrôlent le flux d’information. La porte d’oubli décide quelles informations passeront, la porte d’entrée détermine quelles valeurs candidates seront ajoutées à l’état, et la porte de sortie choisit quelles informations seront exportées pour les étapes suivantes.
LSTM vs Transformer : quel choix en 2025 ?
Les Transformers dominent de nombreuses applications NLP à grande échelle, mais les LSTM restent pertinents pour des tâches avec des ressources limitées, des contraintes de latence ou des jeux de données modestes. Dans les systèmes hybrides, on peut combiner les forces des deux approches.
Comment démarrer avec LSTM dans TensorFlow/Keras ou PyTorch ?
Commencez par des tutoriels de base sur les couches LSTM disponibles dans Keras ou PyTorch. Expérimentez avec des jeux de données simples (par exemple, prévision de séries temporelles) et passez progressivement à des modèles plus complexes avec des mécanismes de régularisation et de dropout.


