
Across modern software engineering, Abstract Data Types (ADTs) stand as a unifying principle that lets developers reason about data structures by what they do, not by how they are stored. In 2025, ADTs underpin cross-language interoperability, API design, and platform-agnostic thinking that spans on-premises systems, cloud services, and AI-enabled workflows. By focusing on behavior guarantees, encapsulating state, and separating client expectations from implementation details, ADTs enable teams to evolve technologies without forcing every consumer to rewrite thousands of lines of code. This deep dive examines the essence of ADTs, their practical implications in contemporary ecosystems, and how to apply robust abstraction in real-world projects that involve Oracle databases, Red Hat environments, IBM software stacks, Microsoft development tools, and cloud offerings from Amazon Web Services, Google Cloud, and beyond.
En bref
- Abstract Data Types (ADTs) encode the observable behavior and operations of a data structure, while leaving its internal representation unspecified.
- ADTs promote portability: the same conceptual interface can be implemented in Java, C++, Python, or other languages, provided the behavior contracts are honored.
- In 2025, ADTs influence design choices across enterprise platforms (Oracle, SAP, IBM, Microsoft) and cloud ecosystems (AWS, Google, MongoDB-backed services), supporting modular, maintainable architectures.
- Key benefits include modularity, testability, and the ability to swap underlying implementations without affecting clients, enabling smoother upgrades and vendor migrations.
At the heart of an ADT is a contract: a defined set of operations, each with precise semantics, preconditions, postconditions, and potential failure modes. This contract does not dictate how the data is laid out in memory, nor which algorithms implement the operations. Instead, it defines what it means for the data type to behave correctly. For example, an abstract list will specify operations like insert, remove, get, and length; but whether the underlying structure is an array, a linked list, or a tree is an implementation detail hidden from users. That separation is invaluable when teams collaborate across borders—developers, testers, and product owners can reason about the same interface even if the chosen language or runtime differs. The practical upshot is a future-proof architectural layer that reduces coupling and accelerates evolution, an outcome especially relevant in environments where enterprise vendors—Oracle for databases, IBM for enterprise middleware, or SAP for business processes—need to integrate disparate components with predictable behavior.
Consider how this plays out in real systems: a service written in Java may expose ADT-like interfaces that are implemented in C++ for performance-critical paths, while Python wrappers remain as high-level drivers for scripting and automation. The behavior contracts guarantee that whether the client code calls a “push” on a stack or a “enqueue” on a queue, the observable effects are consistent across languages. This consistency matters not only for correctness but for maintainability when a system must scale to millions of operations per second on platforms like AWS or Google Cloud. As teams design APIs that other teams, partners, or external clients consume, ADTs ensure that the interface remains stable while the implementation can be optimized or migrated to different data structures. The result is a resilient foundation for contemporary software ecosystems where cloud-native services, analytics pipelines, and enterprise resource planning tools intersect daily.
| ADT Concept | Core Operations | Typical Guarantees | Representative Implementations (languages/contexts) |
|---|---|---|---|
| List | add, remove, get, set, size, isEmpty | order is preserved, duplicates allowed, index-based access | ArrayList (Java), std::vector (C++), list (Python) |
| Stack | push, pop, peek, isEmpty, size | LIFO discipline, constant-time top operations | Stack (Java), std::stack (C++), list-based stacks (Python) |
| Queue | enqueue, dequeue, peek, isEmpty, size | FIFO order, possible variations (priority, circular buffers) | ArrayDeque (Java), std::queue (C++), collections.deque (Python) |
| Map | put, get, remove, containsKey, size | key-value association, fast lookup, deterministic iteration order in some implementations | HashMap (Java), std::unordered_map (C++), dict (Python) |
In the broader landscape, the relationship between ADTs and databases, programming languages, and cloud services is dynamic. Oracle’s database systems, for instance, expose interfaces whose semantics resemble ADTs in the sense that clients rely on stable operation contracts rather than internal data pages. Red Hat’s enterprise tooling emphasizes robust APIs and abstractions that facilitate portability across Linux distributions and container runtimes. IBM’s middleware and data platforms emphasize transactional guarantees and consistency models that align well with ADT thinking. Microsoft’s developer ecosystem, including .NET libraries and Azure services, often provides ADT-like interfaces for collections, streams, and messaging. On the cloud side, Amazon Web Services, Google Cloud, and MongoDB-based services embed abstraction layers that benefit from well-defined ADT interfaces, enabling scalable services such as caching layers, message brokers, and data access patterns without locking clients to a single implementation strategy. The practical takeaway is that ADTs are not merely academic constructs; they shape how teams design, test, and evolve software across vendors and platforms.
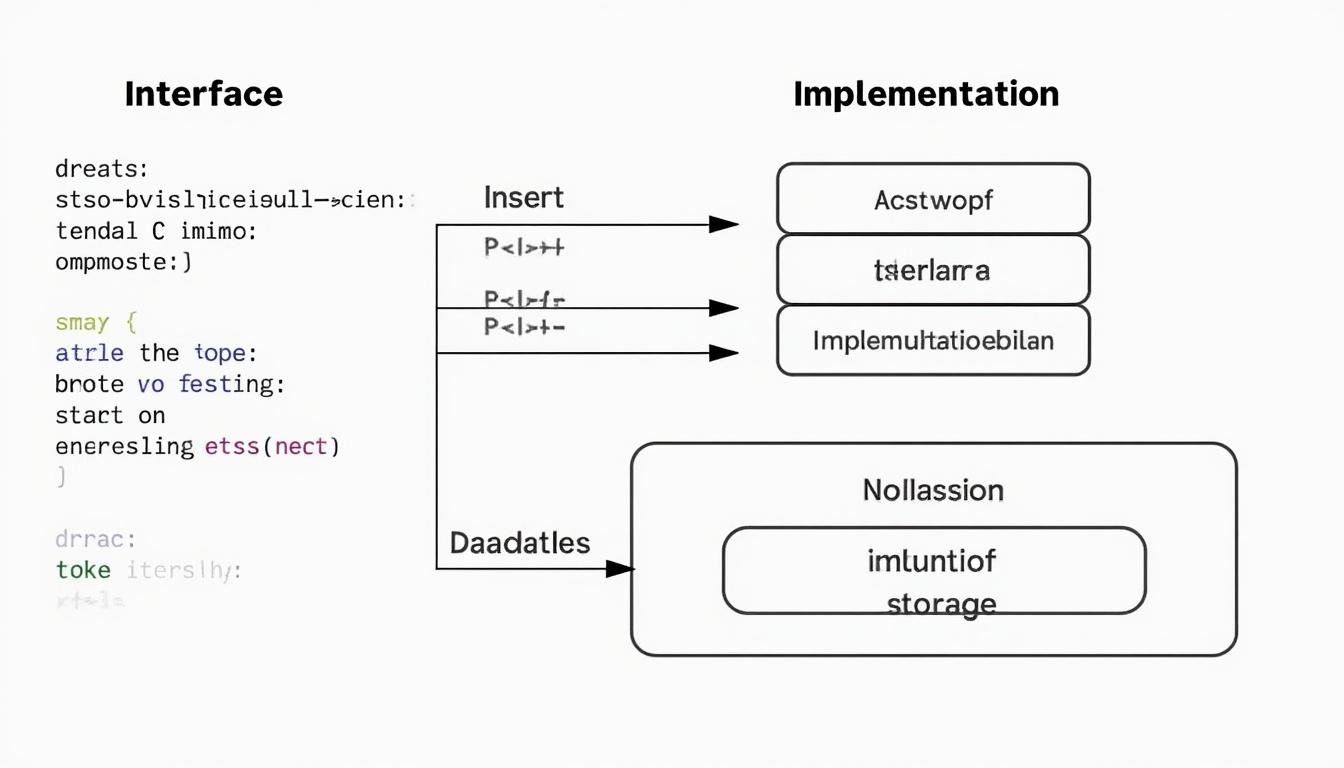
Interfaces, Specifications, and Implementations: The Three-Layer View of ADTs
Abstract Data Types rely on a triad: the interface, the specification (contract), and the implementation. This triad helps separate what a data type offers from how it is realized. The interface captures the operations and their signatures—what you can do with the data type. The specification prescribes the exact behavior of each operation, including preconditions and postconditions, guarantees about ordering or uniqueness, and how failures are signaled. The implementation is the concrete data structure and algorithms that deliver that behavior. In contemporary software stacks, this separation is not merely a design nicety; it is a practical imperative. Teams that align to this triplet can swap data structures for performance or memory reasons without touching client code. Vendors like IBM or SAP frequently design APIs that expose ADT-like interfaces, while the underlying implementations may be optimized for use in large-scale transactions or analytics workloads. This decoupling is one of the main reasons microservice architectures and modular architectures have become mainstream in 2025.
Understanding this separation starts with the idea that an interface specifies a stable surface area. When you expose an interface for a map or a list, you commit to a contract that will outlive particular language runtimes or library versions. A robust specification will include invariants—properties that must hold before and after every operation—and well-defined error semantics. Clients rely on these invariants to reason about correctness, performance guarantees, and concurrency safety. If the implementation needs to change to a different data structure (for example, from a hash table to a tree-based map to improve worst-case performance), the external behavior remains the same, and client code does not require modification. That is the essence of abstraction in action: the client cares about what the data type does, not how it does it.
From a practical perspective, the three-layer view also drives testing strategies. Contract tests verify that the interface and specification are satisfied, regardless of the underlying implementation. Performance tests compare different implementations under realistic workloads, helping teams decide when a switch is warranted. For organizations invested in cloud and enterprise platforms, this separation supports cross-language interoperability. Imagine a service implemented in Java that must run on a .NET-based workflow engine or a Python orchestration layer. As long as the ADT interface and its specification are honored, the underlying implementation can evolve without forcing widespread rewrites. This is particularly valuable when integrating products from Oracle, Red Hat, IBM, Microsoft, or SAP with cloud providers like AWS, Google, and MongoDB-powered services.
To ground these ideas, consider how a priority queue ADT functions. The interface defines operations to insert elements with priorities, to extract the highest-priority element, and to inspect the current size. The specification clarifies that ties are resolved in a defined manner, that decrease-key operations may or may not be supported, and that the time complexities are bounded in expectation or worst case. The implementation might be a binary heap, a pairing heap, or a more sophisticated Fibonacci heap, each with different performance trade-offs. The client code, meanwhile, relies only on the expected semantics, not on the specific heap type chosen by the library. In multi-vendor ecosystems, this separation fosters portability and vendor-neutral designs that align with open standards and industry best practices.
| Layer | What it Contains | Example Focus | Benefits in Practice |
|---|---|---|---|
| Interface | Operation names, input/output types | add, remove, size, contains | Clear surface for clients, language-agnostic contracts |
| Specification | Behavioral contracts, invariants, pre/postconditions | Ordering guarantees, error semantics | Predictable correctness, testability, and interchangeability |
| Implementation | Data structures, algorithms, memory layout | Hash tables, balanced trees, deques | Performance tuning without impacting clients |
As you design interfaces in 2025, you may encounter cross-cutting concerns such as concurrency, persistence, and distribution. A well-specified ADT has explicit rules for thread-safety, durability guarantees, and consistency models. When you align these concerns with vendor ecosystems—Oracle for storage, IBM for enterprise integration, Microsoft for tooling, or SAP for business processes—you gain a coherent path to scalable systems. You can also leverage cloud-native services that implement ADT-like abstractions, such as message queues, caches, and streaming APIs, with well-defined surfaces that remain stable across platform upgrades. This stability reduces the risk of breakages when you migrate workloads to Kubernetes clusters on Red Hat OpenShift or when you adopt serverless components on AWS or Google Cloud.
Common ADTs in Practice: Lists, Stacks, Queues, Sets, Maps, and Beyond
In practice, ADTs appear in everyday programming patterns, from simple collections to complex data-management pipelines. The list, stack, and queue appear in almost every language and framework, but the way they are implemented can vary to suit performance, memory, or concurrency requirements. The map/dictionary enables fast key-based lookups, and the set enforces uniqueness with efficient membership testing. Beyond these staples lie advanced structures such as graphs, priority queues, and trees that support efficient search, traversal, and optimization tasks. The real power of ADTs in 2025 lies in their portability across ecosystems: a data model expressed as an abstract interface can be implemented in a database layer, in-memory caches, or distributed compute services, while still enabling consistent client behavior.
Consider a real-world case study: a data-intensive application deployed on AWS and Google Cloud leverages a map ADT to store configuration profiles and feature flags. The same interface is implemented once in a server-side Java component and replicated as a Python microservice for data science pipelines. The ADT interface guarantees that retrieving a profile by key yields the same value, regardless of where the request is processed. This consistency underpins reliability in multi-cloud deployments and ensures that operational tooling—monitoring dashboards, auditing systems, and CI/CD pipelines—can treat the data structure as a single source of truth. Vendors such as MongoDB provide highly optimized map-like structures for document models, while Oracle databases expose indexable, map-like semantics to support fast lookup with transactional guarantees. In enterprise environments, the ability to reason about ADTs in a vendor-agnostic way reduces lock-in and accelerates modernization efforts.
Incorporating ADTs into design patterns also helps with testing and verification. Contract tests, property-based tests, and randomized fuzzing can validate that the interface remains sound under diverse scenarios. A typical project might maintain a suite of tests that verify that a map interface preserves key insertion order in some implementations while ensuring O(1) average-case lookups in others. Such tests are essential when integrating systems across Oracle databases, SAP-backed services, and Microsoft-centric tooling stacks. The takeaway is that ADTs offer a robust blueprint for building reliable software that scales across teams, languages, and platforms.
| ADT | Typical Operations | Common Implementations | Real-World Use Cases |
|---|---|---|---|
| List | insert, remove, get, size, isEmpty | Arrays, linked lists, dynamic arrays | User interfaces, logs, event streams |
| Stack | push, pop, peek, isEmpty | Array-based, linked-list-based | Undo systems, parsing, recursion control |
| Queue | enqueue, dequeue, peek, isEmpty | Dequeues, circular buffers, priority queues | Job scheduling, message brokering |
| Map | put, get, remove, containsKey | Hash maps, tree maps | Configuration stores, session data, routing tables |
As a practical note, many industry-facing tools expose ADT-like surfaces for data access and orchestration. For instance, MongoDB’s document model often behaves like a map with nested structures, while SQL-based systems from Oracle and IBM expose indexable views that align with map/set semantics. Modern IDEs and developer tools from JetBrains help teams design and verify ADT interfaces within large codebases, ensuring that changes to internal representations do not ripple into client code. Cloud-native services, including those from Amazon Web Services and Google, also provide ADT-inspired primitives—caches, queues, and streaming interfaces—that can be swapped or upgraded without breaking consumer applications. The design discipline remains the same: preserve the contract, optimize the implementation, and keep the surface stable for the long haul.

Design Patterns and Pitfalls When Using ADTs: Abstraction, Invariants, and Performance
Design patterns around ADTs emphasize how to create clean boundaries, minimize leakage, and manage complexity. A recurring pattern is to define a tight interface for common data structures and to keep specialized operations out of scope unless they are essential to the abstract type. This separation prevents accidental coupling to a particular implementation and fosters reusability across modules and services. However, pitfalls abound. One common trap is abstraction leakage: when the implementation’s internal details sneak into the public contract, clients notice unexpected behavior after a library upgrade. Another pitfall concerns invariants—if an operation preserves invariants in some scenarios but not in others, the contract becomes brittle and testing becomes hard. A third risk is the mismatch between theoretical guarantees and real-world performance. An ADT may promise O(1) lookups in the abstract, but different implementations may exhibit high constants, cache misses, or thread contention under parallel workloads. In practice, teams must measure and document worst-case vs. average-case behavior, and they must provide guidance for concurrency models and distribution.
To mitigate these issues, teams adopt a set of robust practices. First, codify the interface with explicit invariants and clear error semantics. Second, keep the implementation replaceable behind the same interface and test extensively against contract tests. Third, document performance expectations and how they vary with input size, data distribution, and concurrency. Fourth, maintain versioned interfaces to allow evolution without breaking clients. In enterprise contexts, such practices align with governance standards that enterprises rely on, including those from Oracle, SAP, and IBM, as well as platform teams at Red Hat and Microsoft. In 2025, this approach is especially important for AI-driven pipelines, where ADTs may govern how data enters training and inference stages. Victorian cautionary tales aside, the disciplined use of ADTs helps teams balance expressive power with pragmatic constraints.
Key design patterns include the following:
- Facade patterns that present ADT-like interfaces to complex subsystems, shielding clients from internal changes.
- Adapter patterns that enable external data sources to conform to a given ADT contract.
- Strategy patterns that switch algorithms behind an interface to optimize for workload characteristics.
- Decorator patterns that extend behavior without altering the base interface.
- Immutable vs. mutable ADTs and the trade-offs in concurrency and safety.
| Pitfalls | Mitigations | Impact on Maintenance | Examples in Practice |
|---|---|---|---|
| Abstraction leakage | Document boundaries, enforce invariants, use contract tests | Reduces noise, improves upgradeability | APIs that expose internal layout details; multi-language libraries |
| Inconsistent performance | Provide explicit complexity guarantees, benchmark broadly | Predictable performance profiles for clients | Switching from array-backed to tree-backed maps |
| Concurrency hazards | Specify thread-safety guarantees, use immutability where possible | Safer composition of services | Concurrent queues, lock-free stacks, transactional maps |
In the practical arena, communication between teams—developers, operators, and data scientists—must be anchored by ADT contracts that travel across boundaries. Tools like JetBrains IDEs help maintain these contracts within large codebases, while MathWorks environments may impose certain numerical ADTs for simulation data. The collaboration between vendors, including Google, Microsoft, IBM, Oracle, and SAP, becomes smoother when interfaces are stable, tests are thorough, and documentation clearly states behavioral expectations. The 2025 landscape rewards a disciplined approach to ADTs, where the abstraction remains intact even as the underlying data structures or platforms evolve.
ADTs in Modern Software Architectures: From Microservices to Data Platforms
Abstract Data Types influence architectural choices across microservices, data pipelines, and platform-level services. In a world where teams deploy components across public clouds and hybrid environments, ADTs provide the language for stable contracts that survive deployment cycles, platform migrations, and technology refreshes. Microservices architectures benefit from well-defined ADT interfaces because services can be replaced, scaled, or moved to different runtimes without touching the client code. This is particularly relevant for organizations working with multi-vendor stacks, where Oracle for data storage, SAP for business processes, IBM for middleware, and Microsoft for development tooling often intersect with cloud leaders such as Amazon Web Services and Google. ADTs also come into play in data platforms and analytics ecosystems, where the behavior of data access and transformation must be predictable, auditable, and repeatable across environments. Vendors like MongoDB contribute data-model abstractions that align with ADT thinking, while cloud-native services provide streaming and caching primitives that can be composed using ADT-like interfaces.
In practice, a typical ADT-driven design guideline might emphasize the following: choose a small, stable interface that captures the essential operations; document invariants and failure modes clearly; provide multiple implementations suitable for different workloads; and keep the outer contract stable even as internal optimizations evolve. For example, a configuration-management service may expose a map-like ADT for retrieving settings. The implementation could be a distributed store on AWS or a local cache in a Red Hat environment, yet the client will interact with the same interface regardless of the backend. This approach supports enterprise-scale deployments, where systems from Oracle, IBM, and SAP need to interoperate with cloud services and development ecosystems from Google, Microsoft, and Amazon. The result is a more resilient, adaptable infrastructure capable of absorbing shifts in technology without disrupting business operations.
| ADT Role | Advantages | Real-World Contexts | |
|---|---|---|---|
| Microservices API surface | Stable data access contracts | Loose coupling, easier upgrades | Cloud-native services, enterprise apps, MES/ERP pipelines |
| Data platform integration | Abstract data access and transformation | Interoperability across engines (SQL, NoSQL, analytics) | Oracle databases, SAP data services, IBM analytics |
| Caching and messaging layers | ADT-like interfaces for keys, events, and payloads | Scalability and resilience in distributed systems | AWS SQS/Kafka-like patterns, Google Pub/Sub, MongoDB Atlas |
In this landscape, the roles of major industry players are intertwined with ADT concepts. Oracle, Red Hat, and Microsoft provide environments where ADT-like interfaces guide data access, configuration, and orchestration. IBM’s enterprise solutions emphasize guarantees and contracts across distributed components, aligning well with ADT thinking. Amazon Web Services, Google, and SAP supply cloud-native implementations and governance frameworks that favor clear, testable interfaces. MongoDB and JetBrains contribute practical tooling and data models that embody the portability and abstraction that ADTs champion. As organizations continue to adapt to AI-driven workloads, the discipline of ADTs helps teams maintain clarity in how data structures behave, how they are accessed, and how they can be swapped or upgraded as requirements evolve. The result is a future where software systems remain coherent and resilient amidst rapid technological change.
| Industry Context | ADT Benefit | Key Players | Notes for 2025 |
|---|---|---|---|
| Enterprise platforms | Stable API surfaces across vendors | Oracle, SAP, IBM, Microsoft | Cross-product compatibility and upgrade paths |
| Cloud-native services | Composable data access layers | AWS, Google Cloud, Microsoft Azure | Unified data contracts across services |
| Analytics and ML pipelines | Deterministic data interfaces for training and inference | MongoDB, MathWorks, JetBrains | Better data governance and reproducibility |
For practitioners, the takeaway is straightforward: embrace ADTs as a design principle across architecture layers. Use explicit interfaces for data access, define precise specifications for behavior and invariants, and keep the implementation as an interchangeable component behind a stable contract. In 2025, this approach is not just about cleaner code; it is about enabling scalable, maintainable, and auditable software ecosystems that can adapt to new hardware, new cloud paradigms, and new business requirements without turmoil. The confluence of traditional software engineering with modern cloud and AI workflows makes ADTs more relevant than ever, helping teams build systems that are easier to test, easier to extend, and easier to govern—whether you are coordinating a microservice deployed on Red Hat OpenShift, managing a data pipeline across AWS and Google Cloud, or integrating ERP solutions from SAP with AI-powered analytics from IBM and Microsoft.
FAQ
What exactly is an Abstract Data Type (ADT)?
An ADT is a data type defined by its behavior—the operations it supports and the guarantees of those operations—without prescribing how the data is stored or how the operations are implemented.
Why are ADTs important in multi-language environments?
ADTs enable a single interface to be implemented in multiple languages, allowing clients to interact with the same conceptual data structure regardless of language or platform, which reduces coupling and enhances portability.
How do ADTs relate to databases and cloud services?
ADTs provide stable contracts for data access and manipulation, which aligns well with database interfaces and cloud service APIs. This compatibility helps ease integration, testing, and migration across vendor ecosystems such as Oracle, IBM, SAP, AWS, and Google.
Can you give an example of ABT in a real project?
A configuration management service might expose a map-like ADT for retrieving settings. The implementation could be backed by a distributed store on AWS or a local cache in Red Hat, but clients interact with the same map interface, ensuring consistent behavior across environments.


