
The understanding of reinforcement learning (RL) has evolved into a cornerstone of intelligent decision-making across industries. By 2025, RL has moved from academic curiosities to practical tools powering autonomous robotics, personalized recommendations, and strategic optimization. The core idea remains simple yet powerful: an agent learns to make better choices by interacting with an environment, receiving feedback, and updating its strategy over time. Trailblazers in the field—OpenAI, DeepMind, Google AI, and IBM Watson, among others—have demonstrated how agents can improve through exploration and feedback loops, enabling systems to perform complex tasks without explicit programming for every scenario. This article unpacks the fundamentals, traces the path from toy problems to real-world deployments, and highlights the ecosystem shaping RL today. For further reading, you can explore related analyses at Exploring the Depths of Reinforcement Learning and other AI insights across the links below.
En bref:
- RL enables agents to learn optimal behavior through trial and error by interacting with an environment.
- The core components are the agent, the environment, actions, rewards, and a policy that guides decisions.
- Key methods include model-free and model-based approaches, with Q-learning and policy gradients among the most influential algorithms.
- Real-world RL spans robotics, gaming, finance, and personalized services, but faces sample efficiency, safety, and generalization challenges.
- Major players—OpenAI, DeepMind, Google AI, IBM Watson, NVIDIA, and more—are advancing RL research and deployment at scale.
Understanding Reinforcement Learning: Core Concepts and How It Learns
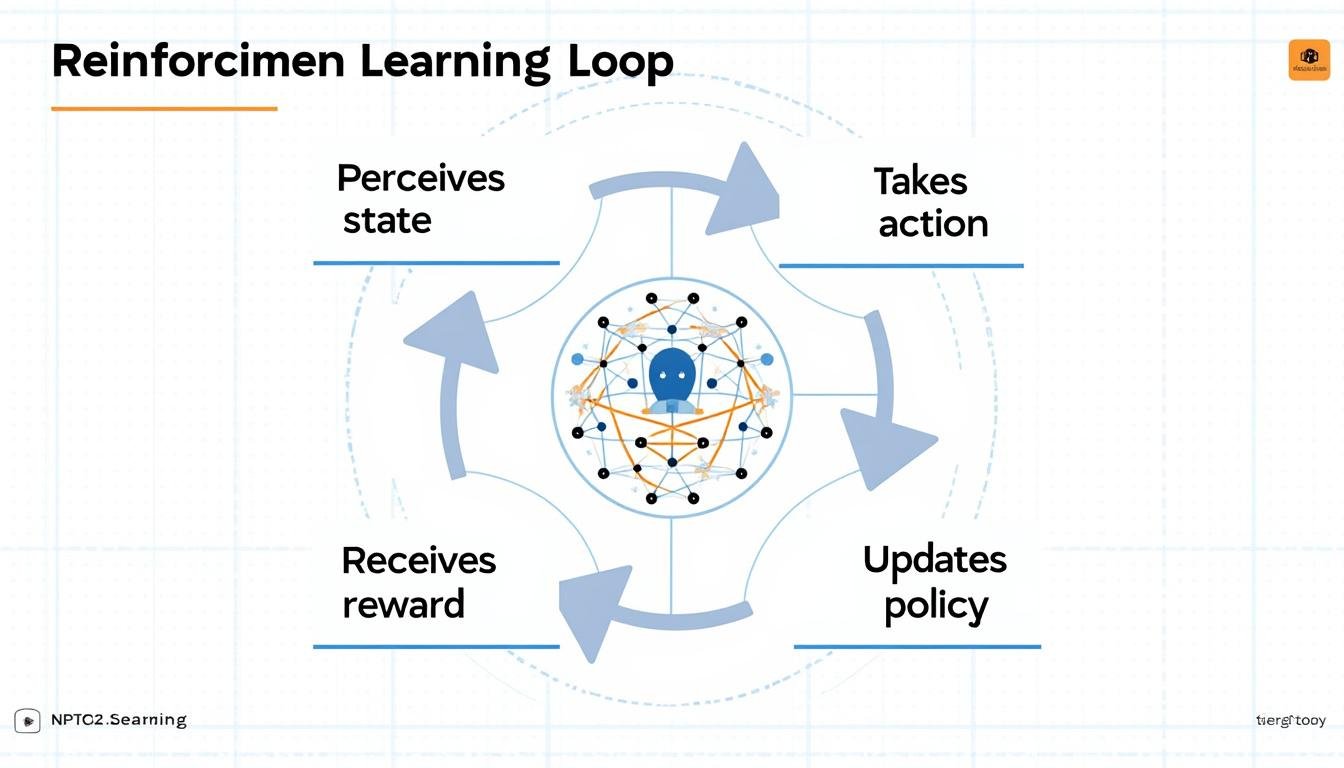
Reinforcement learning treats decision-making as a sequential process. An agent observes a state of the world, selects an action, and transitions to a new state, receiving a numeric reward in return. The agent’s goal is to maximize cumulative rewards over time, which it does by learning a policy—a mapping from states to actions. In many formulations, a value function estimates how good a state or action is, helping the agent plan ahead. RL distinguishes itself from supervised learning by emphasizing learning through interaction rather than from a fixed dataset. Two broad families exist: model-free methods that learn without a full model of the environment (e.g., Q-learning, SARSA, policy gradient methods) and model-based approaches that construct an internal model to simulate outcomes and plan more efficiently. This balance between exploration and exploitation, along with temporal-difference updates, forms the skeleton of modern RL practice.
- Agent: the learner and decision-maker.
- Environment: everything the agent interacts with; dynamics determine state transitions.
- Policy: the strategy that selects actions based on the current state.
- Reward: the feedback signal guiding improvement.
- Exploration vs. exploitation: a trade-off between trying new actions and leveraging known good actions.
| Concept | Definition | Real-world example |
|---|---|---|
| State | Current observation of the environment | Robot arm position and grip status during a pick-and-place task |
| Action | Decision taken by the agent | Move left, rotate gripper, or extend a robotic arm |
| Reward | Numerical signal indicating action quality | Positive reward for a successful grasp; negative reward for a collision |
From Toy Problems to Real-World RL: Tasks, Environments, and Trade-offs
RL research often starts with simplified environments to understand core concepts, then scales up to tasks that resemble real-world complexity. Toy problems like Grid World or continuous control benchmarks allow rapid experimentation, but success in the lab does not guarantee transfer to industry. The jump from synthetic settings to practical deployments involves handling noisy data, partial observability, safety constraints, and long-horizon planning. Environments such as Unity ML-Agents provide a bridge between game-like simulations and physical systems, enabling actors to develop robust policies before real-world rollout. In 2025, the momentum around RL is powered by major cloud and hardware platforms, with NVIDIA GPUs and Microsoft Azure AI or Amazon Web Services backing scalable training, while specialized toolkits from OpenAI and Google AI push the boundaries of efficiency and sample usage. For deeper context, explore open analyses at AI Innovations Hub and related resources.
- Toy environments accelerate theory-to-practice transfer.
- Real-world RL demands sample efficiency, safety guarantees, and robust generalization.
- Algorithms vary from value-based methods (e.g., Q-learning) to policy-based approaches (e.g., PPO, A3C).
- Applications span robotics, autonomous systems, and adaptive control in industry.
- Open-source platforms and cloud services enable rapid experimentation at scale.
| Environment Type | Typical Challenge | Example Task |
|---|---|---|
| Discrete-action domains | Finite action choices; easier exploration | CartPole balancing |
| Continuous-control domains | Large action space; precise control required | Robotic arm manipulation |
| Partially observable settings | Limited state information | Pseudo-vision-based navigation |
Key Players and Ecosystem: OpenAI, DeepMind, Google AI, and Beyond
The RL landscape in 2025 features a vibrant ecosystem where major labs and cloud providers collaborate and compete. OpenAI and DeepMind continue to publish influential frameworks and breakthroughs, while Google AI integrates RL techniques across products and research. Vendors such as NVIDIA, Microsoft Azure AI, and Amazon Web Services offer scalable training and deployment pipelines that accelerate real-world adoption. In addition, specialized groups like Unity ML-Agents, Facebook AI Research, and Baidu Research push domain-specific advancements, from game engines to speech and vision. For a broader perspective, see analyses at Google in the Digital Age and DeepMind Innovations. The interplay among these players shapes the trajectory of RL toward safer, more capable intelligent systems. Readers interested in a cross-section of RL and AI trends can also visit AI Blog insights.
- OpenAI: advancing scalable RL and generalization in agents.
- DeepMind: pushing meta-learning, exploration, and efficient policies.
- Google AI: integrating RL in search, robotics, and ML tooling.
- IBM Watson: enterprise RL applications and decision-support systems.
- NVIDIA: hardware-accelerated RL training and simulation ecosystems.
- Microsoft Azure AI and Amazon Web Services: cloud-scale RL training and deployment.
- Unity ML-Agents: RL in simulation and game-like environments for rapid prototyping.
- Facebook AI Research and Baidu Research: domain-specific RL advances and benchmarks.
| Player | Focus Area | Notable Contributions |
|---|---|---|
| OpenAI | Generalization and scalable RL | Proximal Policy Optimization variants, scalable agents |
| DeepMind | Exploration, meta-learning | Deep RL with model-based components, efficient curiosity |
| Google AI | Applied RL across products | RL in systems, robotics, and tooling |
| IBM Watson | Enterprise RL | Decision-support and optimization in business contexts |
| NVIDIA | Hardware and simulation | DGX/ROP-based training, large-scale simulators |
Ethics, Safety, and the Future of Reinforcement Learning
As RL systems increasingly influence critical decisions, ethical considerations and safety become non-negotiable. Alignment between learned policies and human values, fairness across user groups, and transparency in how policies evolve are essential. Researchers are exploring safe exploration strategies, robust evaluation, and governance frameworks to prevent unintended consequences when RL agents operate in the real world. The future of RL will likely hinge on modular safety brakes, verifiable policies, and a culture of responsible deployment. For readers seeking broader context on AI ethics and governance, see OpenAI’s impact on AI ethics and related discussions in the AI community.
- Safe exploration and robust policy guarantees.
- Fairness and avoidance of biased outcomes in learned behavior.
- Transparency in decision-making and reproducibility of results.
- Governance structures for deployment in sensitive domains.
- Continued research into alignment with human values and societal norms.
| Aspect | Risk/Challenge | Mitigation |
|---|---|---|
| Safety | Unexpected actions in dynamic environments | Safe exploration, constrained policies |
| Fairness | Bias in reward shaping or environment design | Audit trails and diverse evaluation |
| Transparency | Obscure decision processes | Interpretable policies and logging |
What distinguishes reinforcement learning from other ML paradigms?
RL learns by interacting with an environment, aiming to maximize cumulative rewards, whereas supervised learning learns from labeled data and imitation learning focuses on reproducing expert behavior.
How do you choose between model-free and model-based RL?
Model-free methods are simpler and often more robust in uncertain environments but can be sample-inefficient. Model-based approaches can plan ahead and be data-efficient but require accurate environmental models. The choice depends on data availability, safety requirements, and deployment constraints.
What are common real-world RL pitfalls to watch for in 2025?
Challenges include sample inefficiency, transfer across domains, safety during exploration, and ensuring policy updates remain stable in production environments.
Where can I read more about RL innovations and ecosystems?
A set of AI blogs and research portals provide up-to-date insights; see the linked resources in this article for curated analyses and case studies.


