
Dans le paysage de l’intelligence artificielle en 2025, les réseaux neuronaux récurrents (RNN) demeurent des architectures clefs pour le traitement des données séquentielles. Leur capacité à mémoriser des informations passées via des états cachés permet de modéliser des dépendances temporelles complexes, cruciales pour des tâches comme la traduction, la reconnaissance vocale ou l’analyse de séries temporelles. Bien que le phénomène du gradient qui s’atténue ait longtemps freiné l’apprentissage, les avancées telles que les portes des LSTM et GRU, associées à des techniques d’entraînement robustes et à des cadres performants comme TensorFlow, PyTorch et Keras, ont renforcé leur efficacité pratique. Par ailleurs, l’écosystème IA actuel — avec les contributions de DeepMind, OpenAI, Google AI, NVIDIA, Microsoft Research, Hugging Face et IBM Watson — offre des outils et des ressources qui facilitent l’expérimentation et le déploiement des RNN dans des environnements de production.
En bref
- Les RNN exploitent une mémoire interne pour modéliser des dépendances entre des éléments d’une séquence.
- Le déclin du gradient est un défi historique, corrigé par les architectures LSTM/GRU et par des techniques d’entraînement adaptées.
- Les cadres modernes (TensorFlow, PyTorch, Keras) accélèrent l’expérimentation et la mise en production.
- Les usages typiques incluent la traduction, la reconnaissance vocale et l’analyse de séries temporelles en temps réel.
- Le panorama 2025 montre une coexistence avec les Transformers: les RNN restent utiles dans des contextes où la mémoire dynamique et l’efficacité computationnelle sont primordiales.
Mécanismes des RNN: mémoire et flux d’informations dans le temps
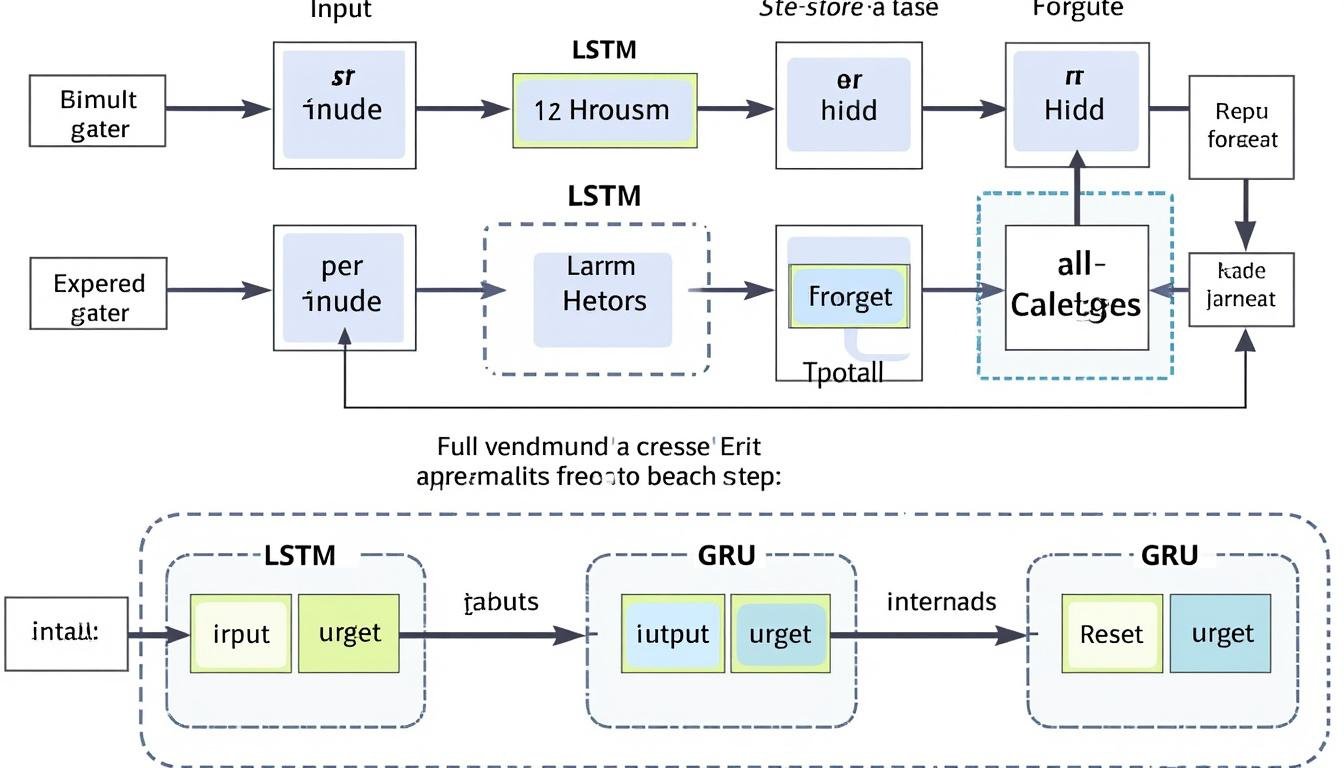
Un RNN traite les entrées une par une et réutilise l’état caché pour transmettre l’information à travers les pas de temps. À chaque étape, l’entrée actuelle et l’état précédent se combinent pour produire une nouvelle représentation, qui peut ensuite être utilisée pour une prédiction ou pour alimenter l’étape suivante. Cette boucle temporelle confère au réseau une mémoire opérationnelle nécessaire pour capter le contexte et les dépendances qui s’étendent au-delà d’un seul élément de la séquence. Néanmoins, l’apprentissage peut devenir instable lorsque les gradients traversent de nombreuses étapes, ce qui a historiquement limité les capacités des RNN sur de longues séquences.
Pour adresser ces limites, les architectures LSTM et GRU introduisent des mécanismes de porte qui filtrent les informations et modulent le flux du gradient. En parallèle, des méthodes comme le Backpropagation Through Time (BPTT) tronqué réduisent le coût et améliorent la stabilité lors de l’entraînement. Les cadres d’aujourd’hui proposent des implémentations optimisées et des outils de débogage qui facilitent le prototypage et le passage à la production.
- Éléments clés: état caché, boucles temporelles, rétropropagation du gradient, portières LSTM/GRU.
- Différences essentielles entre RNN simples, LSTM et GRU.
- Techniques d’entraînement pour la stabilité numérique et la convergence.
| Aspect | Rôle | Notes |
|---|---|---|
| État caché | Stocke les informations sur le pas de temps courant | Base du contexte séquentiel |
| Boucles temporelles | Transmet l’information entre pas de temps | Permet la mémoire opérationnelle |
| Réseaux LSTM/GRU | Gèrent l’apprentissage des dépendances longues | Portes et états internes améliorent la stabilité |
Pour approfondir, ces ressources utiles abordent les principes fondamentaux et les implications pratiques des RNN et de leurs variantes :
- Understanding the intricacies of neural networks: a deep dive into modern AI
- Exploring the power of recurrent neural networks (RNNs) in data processing and analysis
- Exploring the world of neural networks: the key to artificial intelligence
- Understanding key concepts in artificial intelligence
- Unleashing the power of TensorFlow: a comprehensive guide to ML and DL frameworks
Pour enrichir l’intuition visuelle, regardez ces démonstrations :
Pour comprendre les mécanismes de porte et des cas d’usage concrets, voici une autre vidéo explicative :
Évolutions et défis des RNN en 2025
Malgré leurs atouts pour modéliser des dépendances temporelles, les RNN rencontrent des défis directs dans des contextes modernes où les données sont volumineuses et les exigences de latence élevées. Le vanishing gradient et l’exploding gradient restent des soucis d’apprentissage, en particulier sur de longues séquences. Des techniques comme le gradients clipping et le truncated BPTT aident à stabiliser l’entraînement et à limiter la consommation mémoire, mais elles ne remplacent pas le besoin d’architectures plus adaptées à des dépendances longues.
Par ailleurs, la montée en puissance des Transformers a modifié le paysage: pour les tâches nécessitant une très longue mémoire ou une parallélisation efficace, les architectures self-attention surpassent souvent les RNN; toutefois, les RNN conservent une pertinence lorsqu’on cherche des solutions à faible latence ou lorsque l’efficacité matérielle est cruciale. Des recherches récentes explorent des hybrides et des variantes qui combinent les forces des deux paradigmes, ou intègrent des mécanismes d’attention directement dans des RNN pour améliorer les performances sur certaines séries temporelles et systèmes en ligne.
- Défi principal: apprendre des dépendances à long terme sans coût prohibitif; LSTM/GRU et truncated BPTT aident mais ne remplacent pas les choix d’architecture.
- Techniques associées: gradient clipping, régularisation, normalisation et architectures hybrides.
- Contexte industriel: intégration dans des pipelines temps réel et en production, souvent avec des cadres comme TensorFlow et PyTorch.
| Défi | Impact sur l’entraînement | Stratégie |
|---|---|---|
| Vanishing gradient | Difficulté à apprendre des dépendances longues | LSTM/GRU, BPTT tronqué |
| Exploding gradient | Instabilité numérique et mises à jour trop grandes | Gradient clipping, normalisation |
| Coût computationnel | Limite la profondeur temporelle et la vitesse | Truncated BPTT, architectures hybrides |
Cas d’usage et intégrations modernes
Les RNN restent pertinents dans les scénarios où la mémoire séquentielle et les contraintes en ligne jouent un rôle central. Dans les systèmes de production, ils collaborent avec les cadres TensorFlow, PyTorch et Keras pour réaliser des tâches comme la reconnaissance vocale, la génération de texte et l’analyse de séries temporelles en temps réel. De plus, l’écosystème IA s’est enrichi d’acteurs majeurs — DeepMind, OpenAI, Google AI, NVIDIA, Microsoft Research, Hugging Face et IBM Watson — qui publient régulièrement des outils, des jeux de données et des techniques permettant d’optimiser l’entraînement, le déploiement et l’évaluation des modèles séquentiels.
Pour aller plus loin et comprendre comment les RNN s’insèrent dans les architectures modernes, consultez ces ressources et blogs spécialisés :
- Understanding the intricacies of neural networks
- Exploring the world of AI insights and innovations
- Exploring the power of recurrent neural networks in data processing
- Understanding key concepts in artificial intelligence
- A closer look at CNN and related architectures
Les usages concrets aujourd’hui vont des systèmes de traduction en ligne à la modélisation des comportements utilisateurs, en passant par la reconnaissance vocale dans les assistants personnels et l’analyse de séries financières ou industrielles. Des exemples réels montrent que des entreprises et institutions exploitent des pipelines RNN en combinaison avec des cadres comme TensorFlow et PyTorch pour obtenir des résultats compétitifs, tout en explorant des optimisations matérielles avec des accélérateurs de calculs fournis par NVIDIA et partenaires.
Ressources avancées et cas d’étude :
- Exploring the world of neural networks: the key to AI
- Unleashing the power of TensorFlow: a guide to ML and DL frameworks
- Understanding the language of AI: key terminology
- Neural networks mastering diverse learning tasks
- Transforming the future of AI: Transformer and attention philosophy
Qu’est-ce qu’un RNN et comment fonctionne-t-il ?
Un RNN est un réseau qui transmet l’information d’un pas de temps au suivant via un état caché, ce qui lui permet de traiter des séquences. À chaque étape, l’entrée courante est combinée avec l’état précédent pour produire un nouvel état et, éventuellement, une prédiction.
Quels sont les plus grands défis lorsqu’on entraîne un RNN ?
Le principal défi historique est le vanishing gradient (et l’exploding gradient), qui rend difficile l’apprentissage des dépendances longues. Des solutions comme LSTM/GRU, le gradient clipping et le BPTT tronqué aident à stabiliser l’entraînement.
Quand faut-il privilégier un RNN par rapport à un Transformer ?
Les RNN restent utiles lorsque la latence est critique, ou lorsque l’on doit traiter des flux en ligne avec une mémoire locale. Les Transformers excellent en parallélisation et en dépendances longues globales, mais peuvent être plus coûteux en calcul et en données.
Quels cadres et outils recommandés pour démarrer ?
Pour démarrer rapidement, explorez les combinaisons TensorFlow et Keras, ou PyTorch avec des modules LSTM/GRU, tout en consultant les ressources de DeepMind, Google AI et Hugging Face pour des modèles pré-entraînés et des guides pratiques.


