
Le potentiel des réseaux longues mémoire à court terme (LSTMs) pour la prédiction de séquences est une avancée clé dans le domaine de l’intelligence artificielle. Connus pour leur capacité à capturer des dépendances temporelles sur des horizons variés, les LSTMs permettent de modéliser des séries temporelles, du langage et d’autres flux de données séquenciels avec une précision remarquable. En 2025, ces architectures continuent d’évoluer grâce à l’intégration avec les écosystèmes industriels, les outils de calcul distribués et les cadres de développement populaires tels que TensorFlow, Keras et PyTorch. Cet article explore les fondements, les cas d’usage et les meilleures pratiques pour exploiter la puissance des LSTMs dans la prédiction de séquences, tout en fournissant des ressources et des exemples d’implémentation concrets. Pour aller plus loin dans les concepts d’IA et les architectures neuronales, vous pouvez consulter des ressources complémentaires comme les pages sur les concepts clés de l’IA, la capacité des réseaux neuronaux à maîtriser des tâches diverses, ou un glossaire de terminologie AI. Ces ressources enrichissent la compréhension des mécanismes et des défis inhérents aux modèles séquentiels. Pour une vue plus large sur les architectures réseaux, reportez-vous à l’exploration des réseaux neuronaux et à le vocabulaire AI.
En bref
- Les LSTMs déverrouillent la mémoire à long terme dans les données séquentielles, améliorant la prédiction sur des horizons variés.
- Dans l’industrie, ils s’intègrent aux frameworks TensorFlow, Keras et PyTorch et s’appliquent à des domaines comme la finance, la santé et la maintenance prédictive.
- Les défis actuels incluent la gestion de grandes séquences, la régularisation et les coûts de calcul, mais les approches comme les variantes d’attention et les architectures hybrides offrent des solutions prometteuses.
- Les cas d’application s’étendent du traitement du langage naturel à la prévision de séries temporelles, en passant par la détection d’anomalies et le contrôle robotics.
- Pour explorer ces sujets, consultez des ressources spécialisées et des cas d’usage réels disponibles sur des plateformes d’apprentissage et des blogs techniques de référence.
Exploring the Power of Long Short-Term Memory Networks (LSTMs) for Sequence Prediction: Fondements et applications pratiques
Les LSTM ont été conçus pour éviter le problème du gradient qui disparaît lors de l’apprentissage sur de longues séquences, permettant à des cellules mémoire d’apprendre quand oublier et quand conserver l’information. Leur structure repose sur des portes—input, forget et output—qui régulent le flux d’information et protègent le « cell state » des perturbations inutiles. Dans le cadre de la prédiction de suites temporelles, ces mécanismes permettent d’intégrer des tendances à court et à long terme, ce qui augmente la précision des prévisions lors de scénarios complexes, tels que les séries boursières, la demande énergétique ou les séries climatiques. Au fil des années, les chercheurs et les ingénieurs ont enrichi ces architectures avec des variantes plus performantes et des techniques d’attention pour mieux modéliser les dépendances non linéaires.
- Conception et fonctionnement: cell state persistant, gates qui modulent l’information, et mécanismes de mémoire réutilisable.
- Applications clés: prévision de séries temporelles (finance, énergie), modélisation du langage et traduction, détection d’anomalies dans l’IoT.
- Intégration technologique: déploiement sur TensorFlow, Keras, et PyTorch, avec des APIs dédiées et des outils de débogage avancés.
- Enjeux pratiques: longueur des séquences, choix des hyperparamètres, coûts de calcul et risques de surapprentissage sans régularisation.
| Aspect | Explication | Impact sur la prédiction |
|---|---|---|
| Gates | Contrôlent l’information entrant et sortant, et la mémoire à mémoriser. | Améliore la stabilité lors de l’apprentissage sur des longues séquences. |
| Cell State | Stocke les informations pertinentes à travers le temps. | Réduit l’effet du gradient qui disparaît et favorise la continuité des dépendances. |
| Régularisation | Dropout, reg, et normalisation pour éviter le surapprentissage. | Meilleure généralisation sur des données non vues. |
Pour approfondir les concepts, regardez cette introduction qui explique les portes et le flux d’information à travers une cellule LSTM, puis comparez avec des architectures basées sur des réseaux récurrents classiques.
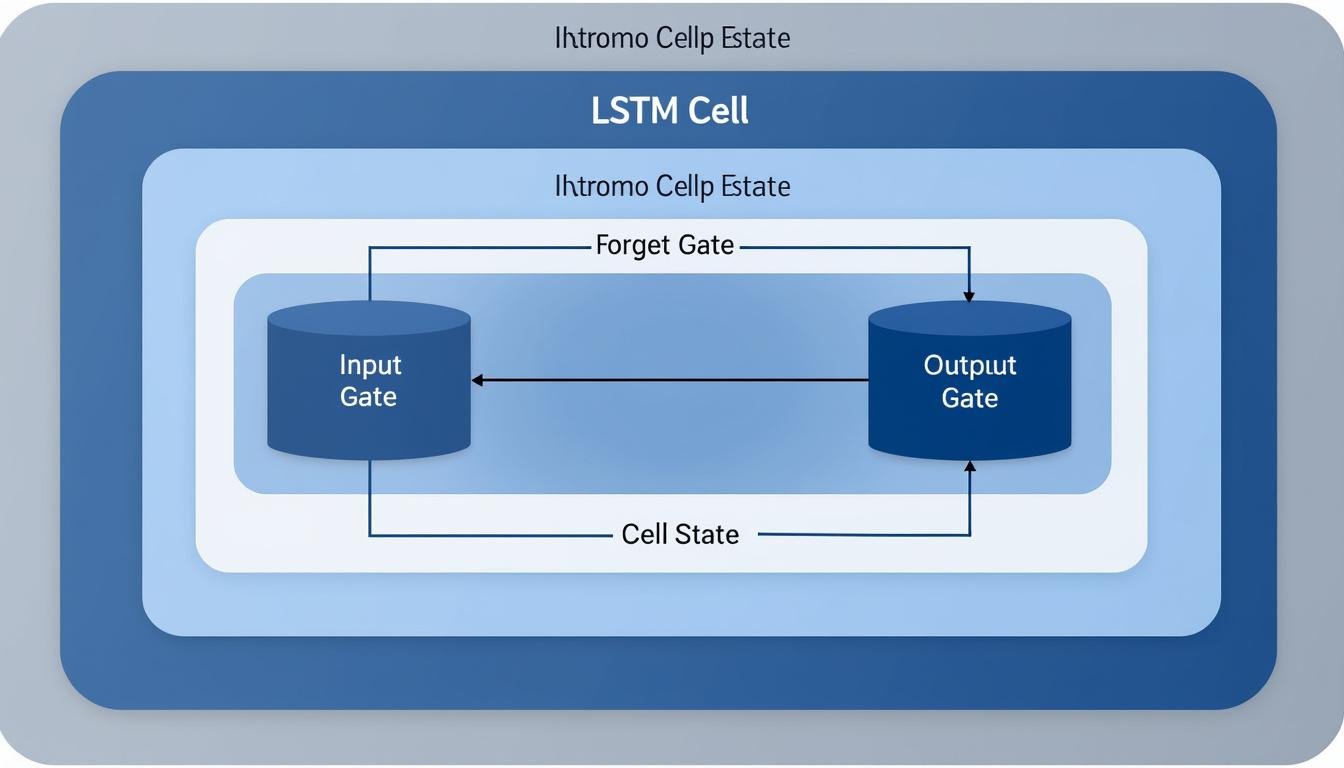
Intégration et cas d’usage concrets
Dans le domaine industriel, les LSTMs alimentent des pipelines de prévision et de détection d’anomalies. Ils se déploient dans des environnements cloud et edge, tirant parti des bibliothèques TensorFlow, Keras et PyTorch pour bâtir des modèles opérationnels. Des ressources complémentaires offrent des explications détaillées sur les concepts avancés et les terminologies associées. Par exemple, des articles et guides sur l’IA et les réseaux neuronaux donnent des repères sur les notions de base et les architectures avancées pour l’optimisation et l’interopérabilité avec les plateformes d’inférence. Pour des lectures élargies, référez-vous aussi à des ressources externes qui décrivent les bases et les nuances des réseaux, en lien avec les dernières évolutions en 2025.
Exemples de ressources et de cas d’usage à consulter (textes en anglais et en français):
- Comprendre les concepts clés de l’intelligence artificielle
- Capacité des réseaux neuronaux à maîtriser des tâches d’apprentissage variées
- Guide de terminologie IA
- Explorer les réseaux neuronaux, clef de l’IA
- Langage de l’IA et terminologie
Intégration pratique et écosystèmes: TensorFlow, Keras, PyTorch et plateformes majeures
Pour tirer le meilleur parti des LSTMs, les développeurs s’appuient sur des cadres de calcul et des services cloud qui facilitent la construction, l’entraînement et le déploiement des modèles séquentiels. TesnorFlow et Keras offrent des API haut niveau pour prototyper rapidement, tandis que PyTorch privilégie une approche impérative et dynamique qui accélère les essais. Sur le plan industriel, des acteurs comme Microsoft, Google AI, OpenAI, NVIDIA, IBM Watson, Amazon Web Services et Facebook AI proposent des outils et des plateformes qui facilitent l’entraînement à grande échelle et le déploiement en production. En parallèle, les ressources documentaires et les cours en ligne s’attachent à démystifier les flux de travail, les bibliothèques associées et les meilleures pratiques pour optimiser les architectures LSTM. Pour aller plus loin, découvrez des analyses et des guides sur les concepts avancés et les termes du domaine sur les ressources listées ci-dessous.
- Examen des frameworks et des bibliothèques: TensorFlow, Keras, PyTorch.
- Conseils de déploiement: attention aux coûts et à la latence lors du passage en production.
- Comparaisons des performances entre architectures et variantes d’attention pour les longues séquences.
- Intégration avec des services cloud et des pipelines MLOps pour la mise à jour continue des modèles.
| Aspect | Intégration technologique | Bonnes pratiques |
|---|---|---|
| API et Framework | Choix entre API haut niveau (Keras) et contrôles bas niveau (PyTorch) | Utiliser la modularité et les callbacks pour le suivi des métriques |
| Entraînement | Utilisation de GPUs et de TPUs, parallélisation des lots | Régularisation et annealing des taux d’apprentissage |
| Déploiement | Intégration CI/CD et inference sur le edge ou le cloud | Choisir les bons services (AWS, Azure, Google Cloud) selon le coût et la latence |
Pour enrichir les scénarios d’application et les considérations pratiques, consultez les ressources suivantes qui illustrent les notions de base et les concepts avancés de l’IA et des réseaux neuronaux:
Cas d’usage et exemples concrets
- Prévision de demande et gestion de stocks dans le commerce de détail avec des flux journaliers et hebdomadaires.
- Analyse de séries de capteurs dans l’industrie manufacturière et la maintenance conditionnelle.
- Modélisation du langage pour des systèmes de réponse et de traduction en temps quasi réel.
| Cas d’usage | Avantages LSTM | Éléments à considérer |
|---|---|---|
| Finance et économie | Capacité à détecter des tendances et des réversions sur plusieurs horizons | Qualité des données et gestion des ruptures de marché |
| Énergie et climat | Prévision énergétique et modélisation climatique avec des dépendances temporelles complexes | Intégration de variables exogènes et de scénarios climatiques |
| Santé et biologie | Analyse de séries temporelles biomédicales et surveillance des patients | Confidentialité et conformité réglementaire |
Défis et perspectives en 2025
- Optimisation des coûts d’entraînement et d’inférence via des architectures hybrides et des techniques d’attention.
- Gestion de très longues séquences et réduction de la latence en production.
- Interopérabilité entre les cadres et les outils d’évaluation et de débogage.
- Éthique et biais dans les modèles séquentiels et les données d’entraînement.
Pour approfondir les notions et les cas d’usage, explorez les articles et les guides disponibles sur les ressources mentionnées ci-dessus et découvrez comment les LSTMs s’intègrent dans les systèmes modernes d’IA et les chaînes de production. L’actualité technique de 2025 met en lumière l’évolution des méthodes et des outils, notamment dans les domaines du cloud, de l’edge et des pipelines MLOps.
Comment les LSTMs gèrent-ils les dépendances à long terme dans les données séquentielles ?
Les LSTMs utilisent des portes pour préserver ou oublier l’information au fil du temps, ce qui aide à maintenir des dépendances pertinentes sur de longues séquences et à éviter le problème du gradient qui disparaît.
Quand préférer une architecture LSTM à une alternative comme GRU ?
Les LSTMs offrent une expressivité plus fine grâce à leurs portes distinctes, ce qui peut être avantageux sur des jeux de données complexes. Les GRU sont plus légers et peuvent bien fonctionner pour des tâches simples ou lorsque les ressources sont limitées.
Quelles sont les meilleures pratiques pour le déploiement d’un modèle LSTM en production ?
Utiliser des pipelines MLOps, surveiller les dérives des données, optimiser l’inférence via quantization ou pruning et tester sur des scénarios réels avec des jeux de données continus.
Quelles ressources ouvrir pour apprendre les concepts avancés des LSTMs ?
Consultez les guides et les articles sur les concepts IA et les architectures réseau, notamment les ressources externes et les blogs techniques cités ci-dessus.


