En bref: Key takeaways for Semi-Supervised Learning in 2025
- Semi-Supervised Learning (SSL) blends a small amount of labeled data with a large pool of unlabeled data to train more capable models while reducing labeling costs.
Semi-supervised learning (SSL) sits at a pivotal intersection in modern AI: it leverages the abundance of unlabeled data alongside a limited set of labeled examples to craft models that generalize more robustly. In 2025, the data landscape is richer and more complex than ever, with organizations facing high labeling costs, privacy constraints, and the need to adapt to shifting environments. SSL provides a pragmatic bridge, enabling systems to learn from patterns in unlabeled data while retaining the guiding signal of a small, trusted labeled subset. This article examines SSL as a mature paradigm, describing its core concepts, practical workflows, and the ways it is reshaping industries. We will explore how SSL techniques have evolved, why they matter for real-world projects, and what practitioners should consider when designing SSL-enabled pipelines. The discussion will reference industry movements, including advances from leading AI labs and platforms, and will weave in examples, case studies, and actionable guidance for 2025 and beyond.
As we move through the sections, you’ll encounter concrete illustrations, modular explanations, and annotated tables that compare SSL techniques. You’ll also find embedded resources to deepen understanding, including foundational readings and practical guides. For readers seeking deeper engagement with the broader AI ecosystem, notable players such as Google AI, OpenAI, DeepMind, Facebook AI Research, Microsoft Research, NVIDIA AI, Amazon Web Services AI, IBM Watson, DataRobot, and Hugging Face frequently contribute to the development and dissemination of SSL techniques and benchmarks. If you are exploring SSL’s fit for your domain, you’ll find recommended readings and practitioner-oriented resources linked throughout the article.
To broaden your understanding, consider exploring additional explanations and glossaries at these readings:
Understanding key concepts in artificial intelligence,
Demystifying AI: A guide to key terminology in artificial intelligence,
A guide to understanding AI vocabulary,
Understanding the vocabulary of artificial intelligence,
Understanding the language of artificial intelligence: A guide to key terms and concepts.
What is Semi-Supervised Learning? Core Concepts, Definitions, and Workflows
Semi-supervised learning embodies a hybrid paradigm that leverages both labeled data and unlabeled data to train predictive models. In practice, practitioners begin with a modest labeled subset, train an initial model, and then “guess” labels for unlabeled examples to augment the training set. This iterative loop continues, refining the model’s understanding as more pseudo-labels are incorporated. The ultimate aim is to achieve performance improvements with far less manual annotation than traditional supervised learning requires. In many real-world settings, unlabeled data outnumbers labeled data by orders of magnitude, making SSL an attractive option for scalable, cost-effective AI deployment.
In this section we dissect the core ideas that underpin SSL, with emphasis on how different families of methods operate and why they matter in practice. Below is a structured exploration of the major components, followed by a detailed comparison table and practical considerations for deployment. We also reflect on how SSL interfaces with contemporary AI ecosystems, including transformers, large language models, and multimodal architectures. The following subsections provide an evidence-based framework for understanding the dynamics of SSL in 2025 and beyond.
The Hybrid Paradigm: When labeled data meets unlabeled data
The strength of Semi-Supervised Learning lies in balancing supervision with discovery. With a small labeled core, a model learns a baseline mapping. The unlabeled set then acts as a reservoir of structural cues: similarities, clusters, and latent manifolds that the initial model might not fully expose. The ability to exploit these cues without explicit labels is what differentiates SSL from both supervised and unsupervised learning. Practically, SSL enables a workflow where data labeling is reserved for the most informative examples, while the bulk of the learning leverages the underlying geometry of the data space. This is particularly powerful in domains like medical imaging or legal text, where labeled samples are expensive or scarce, but unlabeled data is plentiful.
- Key principle: maximize information from unlabeled data without compromising the signal provided by labeled data.
- Impact: improved sample efficiency and better generalization to unseen data
- Risk: if pseudo-labels are biased early, the model can reinforce incorrect patterns.
| Aspect | Typical SSL Approach | Key Benefit |
|---|---|---|
| Data mix | Small labeled set + large unlabeled set | Leverages structure in data to guide learning |
| Labeling signal | Pseudo-labeling or graph propagation | Reduces labeling costs |
| Safety & robustness | Regularization, thresholding | Mitigates error propagation |
| Scalability | Works with large unlabeled pools | Facilitates deployment on big data |
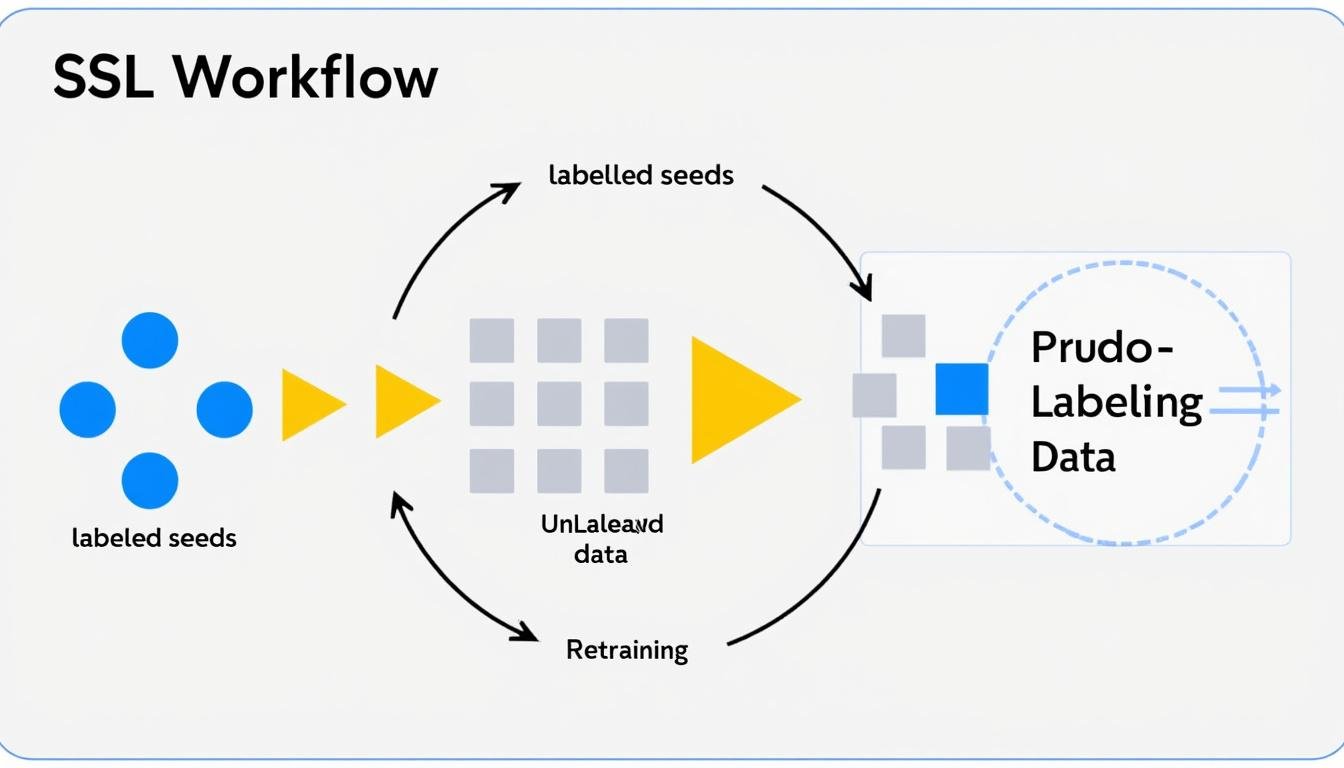
A Typical SSL Cycle: Train, Label, Retrain
In a standard SSL cycle, a model is trained on labeled data and then used to assign pseudo-labels to unlabeled examples. The updated dataset—now including pseudo-labeled instances—forms the input for another training round. This cycle can repeat multiple times, with strategies such as confidence-based filtering, ensemble agreement, and adaptive thresholding used to prune uncertain pseudo-labels. The cycle is designed to grow the model’s competence incrementally, while keeping a careful watch for potential error propagation due to early mislabeling. Across industries, practitioners have shown that well-calibrated SSL cycles can significantly reduce the amount of human labeling required while maintaining or improving accuracy on validation sets.
- Initialization with a small labeled subset establishes a baseline classifier.
- Unlabeled data are converted into pseudo-labels, guided by model confidence and agreement among learners.
- Retraining with the augmented dataset refines decision boundaries iteratively.
For an expansive perspective on SSL foundations, see the curated resources linked below. Additionally, SSL workflows are often embedded within modern ML pipelines that integrate with platforms like Hugging Face and IBM Watson ecosystems, enabling practical experimentation and production deployment. The community continues to refine confidence estimation and mitigation of confirmation bias to strengthen the reliability of pseudo-labels as datasets scale.
Key readings and references:
Understanding key concepts in artificial intelligence,
Demystifying AI: A guide to key terminology in artificial intelligence,
A guide to understanding AI vocabulary,
Understanding the vocabulary of artificial intelligence,
Understanding the language of artificial intelligence: A guide to key terms and concepts.
Further reading and practical depth can be found in field-specific resources and recent benchmark papers that compare methods such as FixMatch, MixMatch, and adaptive thresholding techniques. The literature emphasizes the importance of robust evaluation metrics and careful data curation to quantify SSL gains across domains.
Why SSL Matters in 2025: Cost Efficiency, Generalization, and Real-World Impact
As data ecosystems scale, Semi-Supervised Learning has emerged as a practical answer to two persistent challenges: the cost of labeling and the demand for models that generalize beyond their training distributions. In 2025, SSL is not merely a theoretical curiosity; it is a pragmatic strategy adopted by enterprises seeking to accelerate AI adoption while controlling annotation budgets. The value proposition rests on three pillars: cost efficiency, enhanced generalization, and resilience to domain shifts. When labeled data is scarce or expensive—such as in medical diagnostics, legal analysis, or specialized industrial sensors—SSL offers a viable path to competitive performance without prohibitive annotation efforts. Moreover, industries increasingly demand models that perform well on unseen data, and the continuous flux of real-world environments makes SSL-based learning particularly attractive.
From a business and research perspective, SSL connects with notable industry players and research ecosystems. The collaboration between academic innovations and large-scale platforms—spanning Google AI, OpenAI, DeepMind, Facebook AI Research, Microsoft Research, NVIDIA AI, Amazon Web Services AI, IBM Watson, DataRobot, and Hugging Face—drives scalable, production-ready SSL methodologies. These collaborations help translate advances in pseudo-labeling reliability, consistency regularization, and adaptive thresholding into practical tools and benchmarks that teams can deploy across domains. The resulting ecosystems provide ready-made datasets, transfer learning capabilities, and model evaluation pipelines, making SSL accessible to organizations without deep in-house ML expertise.
For practitioners, the decision to adopt SSL often hinges on a careful cost-benefit analysis. The savings from reduced labeling plus potential improvements in accuracy must outweigh the risks of mislabeling and noise propagation. In 2025, a growing body of evidence suggests that SSL can achieve performance that rivals or exceeds fully supervised models when labeling is limited to a small fraction of the data. This is especially relevant in health informatics, natural language processing, and fraud detection, where unlabeled data is abundant but labels are costly or sensitive. To illustrate, SSL implementations frequently report improvements in sample efficiency, enabling faster prototyping and more rapid deployment cycles across product teams.
Implementation considerations begin with data governance and domain adaptation. SSL systems must be attuned to distribution shifts, label noise, and the possibility of biased pseudo-labels. Techniques such as clustering-based selection, ensemble disagreements, and domain-aware regularization help address these concerns. Beyond technical choices, teams should align SSL strategies with regulatory requirements around privacy and data usage to ensure ethical deployment. The integration of SSL within cloud-native and foundation-model ecosystems is a practical pathway to scale, with cloud providers and AI platforms offering optimized pipelines for SSL training, evaluation, and monitoring.
Key points for 2025 SSL strategy:
- Balance labeling cost with model performance through targeted annotation and pseudo-labeling cycles.
- Use consistency regularization to enforce stable predictions under perturbations, improving robustness.
- Leverage ensemble methods and adaptive thresholds to mitigate error propagation.
- Incorporate domain adaptation and active learning components to respond to distribution shifts.
- Adopt governance practices to ensure privacy, fairness, and accountability in SSL workflows.
For further reading and context on AI terminology and vocabulary, you can consult the same resource set referenced earlier. The SSL landscape evolves rapidly, and staying up to date with the latest benchmarks, datasets, and training regimes is essential for maintaining a competitive edge. See additional resources for deeper dives on terminology and best practices.
- Domain adaptation strategies for SSL in healthcare and finance
- Evaluation metrics beyond accuracy: F1, NMI, ARI, and linear evaluation protocols
- Open-world SSL and handling novel categories in production systems
- Graph-based label propagation in large-scale datasets
- Consistency regularization and modern SSL variants (e.g., FixMatch, FreeMatch)
Core Techniques and Algorithms Driving SSL: Pseudo-Labeling, Consistency Regularization, and Graph Methods
At the heart of Semi-Supervised Learning lies a toolkit of algorithms designed to extract information from unlabeled data while leveraging the sparse labels. Each technique has unique characteristics, data requirements, and suitability for different problem settings. Below, we explore four major families with concrete contexts and illustrative examples, emphasizing their strengths and caveats. As we move through, imagine teams at leading organizations exploring SSL to complement or augment existing supervised pipelines, using libraries and platforms from Hugging Face and cloud providers to operationalize these methods.
Self-Training and Pseudo-Labeling
Self-training uses the model’s own predictions as pseudo-labels for unlabeled data. Early iterations grant higher confidence labels to more certain examples, gradually expanding the labeled pool. This approach is simple to implement and scales well, but it risks reinforcing incorrect predictions if the initial model is weak. Modern improvements focus on confidence calibration, selective labeling, and ensembling to reduce propagating mistakes. In practice, this method aligns well with iterative development cycles where labeling budgets are constrained and rapid prototyping is essential.
- Pros: simple, scalable, cost-effective; can yield large gains with modest labeled data.
- Cons: vulnerability to confirmation bias and error propagation if thresholds are not well-tuned.
- Best used with: moderate labeled data and strong regularization strategies.
In real-world deployments, self-training can be complemented by techniques such as consistency regularization and threshold-based filtering to avoid overcommitting to noisy pseudo-labels. The literature often demonstrates improved performance on image and text classification tasks when these elements are combined with careful validation. Practitioners should maintain a clear separation between training and evaluation data to guard against overfitting to pseudo-labeled samples.
Co-Training and Multi-View SSL
Co-training relies on two (or more) models trained on different views or representations of the same data. Each model labels new examples for the other, creating a collaborative labeling process. This approach is most effective when the views are sufficiently diverse and informative. It can help mitigate the risk of a single-view bias by leveraging complementary information, but it requires careful design to ensure that the distinct views actually contribute new signals rather than redundant information.
- Pros: reduces unilateral bias; can improve robustness when views are independent.
- Cons: depends on meaningful diverse views; may be challenging to implement in some domains.
- Best used in: multi-modal data settings (e.g., text and image) or engineered feature splits.
Open-world SSL and domain adaptation scenarios often benefit from co-training, particularly when one model captures surface patterns while another emphasizes semantic structure. In practice, co-training can be integrated with graph-based methods to propagate label information across a manifold of related data points, enriching the labeling signal without excessive manual annotation.
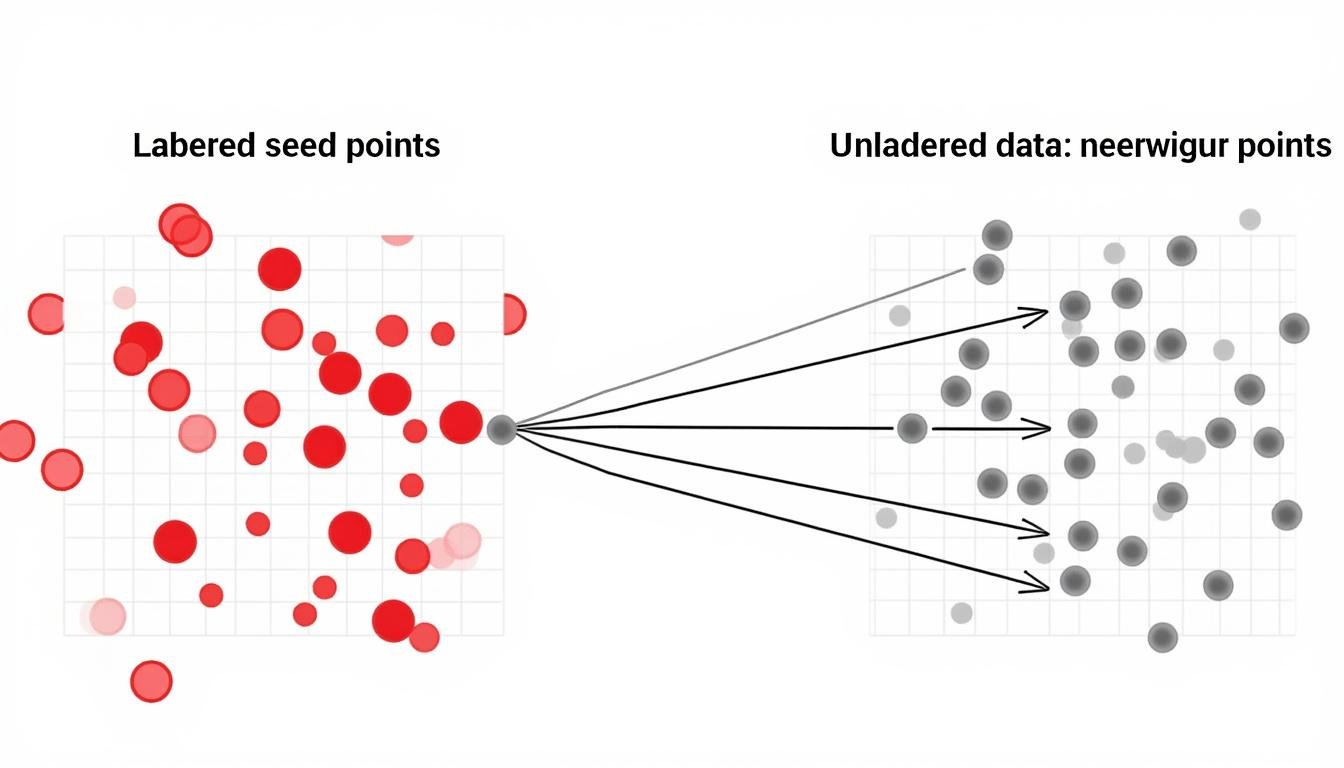
Graph-Based Label Propagation
Graph-based SSL builds a similarity graph where nodes represent data points and edges connect nearby instances. Labels—initially carried by a small set of seeds—propagate through the graph via weighted connections, guided by metrics such as cosine similarity or Euclidean distance. This family of methods is powerful for capturing the intrinsic geometry of the data, making it well-suited to problems with clear cluster structures or manifold shapes. The mathematical foundation—random walks, diffusion processes, and spectral methods—provides strong intuition for why label information spreads across related samples.
- Pros: leverage structure, effective with limited seeds, interpretable diffusion process.
- Cons: scalability challenges on very large graphs; sensitivity to graph construction quality.
- Best used for: datasets where similarity relationships are meaningful and well-defined.
In practice, graph-based SSL often acts as a complementary step to other SSL strategies. It can smooth label assignments across neighborhoods and help stabilize learning when combined with self-training and consistency constraints. Recent research explores scalable graph approximations and hybrid methods that retain the strengths of graph diffusion while maintaining computational efficiency for large-scale data.
Semi-Supervised Generative Models
Generative models—such as Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs)—offer a distinct SSL pathway by modeling the joint distribution of data and labels. By learning latent representations that capture the underlying structure, these models can generate plausible unlabeled samples and leverage them for training. Semi-supervised variants of generative modeling can improve feature representations and promote better generalization, especially when labeled data are scarce. However, they can be more complex to train and require careful balancing between the generative and discriminative objectives.
- Pros: improves representation learning; can produce richer feature spaces for downstream tasks.
- Cons: higher training complexity; potential instability (especially with GANs).
- Best used for: settings where representation quality is paramount and unlabeled data are abundant.
Practitioners deploying generative SSL should consider integration with discriminative heads and downstream fine-tuning on labeled data. The synergy with modern transformer architectures and diffusion models is an active research area, with industry teams exploring how to combine SSL with large foundation models for efficient labeled-data usage.
| Technique | Typical Use-Cases | Strengths | Limitations |
|---|---|---|---|
| Self-Training / Pseudo-Labeling | Text and image classification, multilingual tasks | Scales with unlabeled data; simple to implement | Risk of error propagation; needs calibration |
| Co-Training / Multi-View | Multi-modal data, feature-diverse representations | Reduces bias; leverages complementary views | Requires meaningful views; design sensitivity |
| Graph-Based Label Propagation | Structured data, clustering-friendly tasks | Exploits data geometry; intuitive diffusion | Scalability and graph construction challenges |
| Semi-Supervised Generative Models | Representation learning, data augmentation | Rich latent features; improved generalization | Training complexity; stability concerns |
The SSL toolbox continues to evolve, with new variants that blend consistency regularization, contrastive learning, and adaptive thresholding. In practice, teams often orchestrate several techniques together, crafting custom pipelines that exploit the strengths of each method while mitigating weaknesses. For more on contemporary developments, consult the references provided below and explore how industry players are integrating SSL into production-grade ML stacks.
Industry anchors and practical signals:
- Intersections with Microsoft Research and Amazon Web Services AI for scalable SSL pipelines
- Modeling choices that align with privacy-preserving approaches and federated learning when data sharing is constrained
- Compatibility with transformer-based architectures and the growing role of Hugging Face tools for rapid experimentation
Practical resources and deeper dives can be found in the same set of external readings noted earlier. SSL’s versatility makes it suitable for a broad range of tasks, from sentiment analysis to medical imaging, provided the workflow is carefully designed to guard against noisy pseudo-labels and distributional drift.
SSL in Real-World Domains: Healthcare, NLP, Fraud Detection, and Beyond
Real-world SSL deployments demonstrate the method’s versatility across industries where labeled data is scarce or expensive, yet unlabeled data is abundant. In healthcare, SSL aids imaging and signal analysis by leveraging a handful of expert annotations alongside large repositories of unlabeled scans and records. In natural language processing (NLP), SSL can improve classification, translation, and sentiment analysis with minimal labeled data, especially in low-resource languages. Fraud detection benefits from SSL by learning from vast volumes of unlabeled transactions augmented with a small set of confirmed fraud cases. Across all domains, SSL helps models generalize to unseen patterns, a critical advantage in dynamic operational environments.
- Healthcare: imaging, pathology, and clinical data often exhibit strong unlabeled signal that SSL can exploit.
- NLP: text classification, translation, and entity recognition with limited annotated data.
- Fraud detection and cybersecurity: rapid adaptation to evolving threat patterns using unlabeled data signals.
- Industry ecosystems: SSL toolchains integrate with platforms from NVIDIA AI, IBM Watson, and DataRobot for scalable deployment.
To connect SSL practice with concrete industry contexts, consider the following curated overview of domains and method alignments. The table below highlights representative SSL strategies and their typical benefits in each domain, illustrating how practitioners tailor the approach to data availability and regulatory constraints. For readers seeking further reading or benchmarks, the linked resources provide practical guidance and empirical results from recent studies.
| Domain | SSL Approach | Benefit | Typical Challenge |
|---|---|---|---|
| Healthcare | Graph propagation + selective self-training | Improved diagnostic accuracy with limited labels | Regulatory constraints; data privacy concerns |
| NLP | Consistency regularization + pseudo-labeling | Better text classification with fewer labeled examples | Linguistic diversity; domain shift |
| Fraud Detection | Active learning + co-training | Enhanced anomaly detection with limited confirmed cases | Label latency; evolving fraud patterns |
| Vision | Self-training + contrastive pretraining | Robust features for downstream tasks | Label noise; class imbalance |
SSL achievements in 2025 reflect a broader trend toward integrating robust labeling strategies with scalable unlabeled data utilization. In practice, teams pair SSL with active learning to optimize labeling budgets, and they combine SSL methods with foundation model fine-tuning to maximize data efficiency. This synergy is visible in product pipelines that deploy SSL components alongside large pretrained models, enabling rapid adaptation to new domains with modest labeling effort. To understand how SSL concepts relate to broader AI terminology and practice, the following resources provide structured explanations and practical glossaries:
- Understanding key concepts in artificial intelligence
- Demystifying AI: A guide to key terminology in artificial intelligence
- A guide to understanding AI vocabulary
- Understanding the vocabulary of artificial intelligence
- Understanding the language of artificial intelligence: A guide to key terms and concepts
- Medical imaging workflows that leverage SSL to reduce labeling efforts
- Text classification systems trained with limited domain-specific annotations
- Fraud detection pipelines that integrate SSL with anomaly scoring and human-in-the-loop validation
As SSL adoption accelerates across sectors, practitioners should continually monitor model behavior, update thresholds, and validate against held-out data. The interplay between unlabeled data structure and labeling guidance remains central to SSL’s success, and ongoing experiments—supported by AI labs and platforms—help translate theory into reliable, scalable systems. The following reading list offers deeper insight into SSL techniques and evaluation practices for practitioners seeking to implement robust SSL pipelines in production environments.
Future Trends and Practical Guidelines for Deploying SSL: Evaluation, Robustness, and Ethical Considerations
Looking ahead, several trends are shaping how SSL is applied and evaluated in real-world systems. The field is increasingly attentive to evaluation protocols that reflect deployment realities, including distribution shifts, label noise, and privacy constraints. Researchers are refining certification-style evaluations to quantify not only accuracy but also calibration, fairness, and robustness to adversarial perturbations. In production, SSL systems must integrate with monitoring dashboards, anomaly detectors, and automated retraining schedules to respond to drift. The practical takeaway is clear: SSL is not a one-off training technique but a continuous, lifecycle-oriented approach to learning from data.
- Evaluation sophistication: moving beyond accuracy to include F1-score, clustering metrics (NMI, ARI), and linear evaluation protocols
- Robustness in open environments: handling domain shifts, noisy labels, and distribution mismatches
- Integration with foundation models: aligning SSL with transformers, diffusion models, and contrastive learning
- Privacy and ethics: data governance, privacy-preserving SSL, and bias mitigation
In 2025, the SSL landscape continues to be influenced by innovations from major players in AI research and industry. The interconnectedness of SSL with corporate R&D programs and cloud-based services accelerates experimentation and deployment. For teams seeking practical guidelines, consider a structured approach that includes data curation, careful selection of SSL techniques, robust evaluation, and a plan for ongoing monitoring and updating. The following table summarizes practice-oriented guidelines to keep SSL projects focused and resilient:
| Guideline Area | Practical Actions | Expected Benefit |
|---|---|---|
| Data curation | Prioritize high-quality seeds; curate unlabeled pools with informative variety | Reduces noise and improves signal |
| Technique selection | Combine pseudo-labeling with consistency regularization; consider graph-based refinements for structured data | Improved robustness and generalization |
| Evaluation | Use diverse metrics; run linear evaluation protocols on hold-out sets | Better understanding of transferability |
| Deployment | Monitor drift; implement adaptive retraining; enforce privacy constraints | Sustainable, compliant models |
SSL’s practical viability is enhanced by ecosystem tooling and collaborative innovation. Platforms and toolkits from Google AI, OpenAI, DeepMind, Facebook AI Research, Microsoft Research, NVIDIA AI, Amazon Web Services AI, IBM Watson, DataRobot, and Hugging Face provide research-backed primitives, datasets, and deployment pipelines that help teams implement SSL with greater confidence and speed. The continual cross-pollination of ideas across industry and academia — including the adoption of Flan-style fine-tuning, contrastive learning, and adaptive threshold strategies — keeps SSL at the forefront of data-efficient learning.
To deepen your understanding of SSL terminology and concepts as they relate to production systems, consult the recommended resources earlier in this article. For teams ready to experiment, a pragmatic path involves combining SSL with model monitoring, data governance, and transparent evaluation reporting. The result is a robust, scalable approach to learning from data that respects labeling constraints while capitalizing on the rich information embedded in unlabeled corpora.
FAQ
What exactly is semi-supervised learning?
Semi-supervised learning is a machine learning approach that uses a small labeled dataset together with a much larger unlabeled dataset to train models. The unlabeled data provide structure and patterns that help improve predictions, while the labeled data guide the learning process.
What are the main SSL techniques practitioners should know about?
Key techniques include self-training with pseudo-labels, co-training with multiple views, graph-based label propagation, and semi-supervised generative modeling. Modern practice often combines these with consistency regularization and adaptive thresholding to mitigate error propagation.
How should one evaluate SSL performance in practice?
Evaluation should go beyond accuracy. Use a mix of metrics such as F1-score, precision, recall, ARI/NMI for clustering, and linear evaluation protocols to assess how well representations transfer to downstream tasks.
Can SSL be used in regulated industries like healthcare?
Yes, but it requires careful data governance, privacy-preserving approaches, and validation against regulatory standards. SSL can reduce labeling costs while maintaining high performance, provided robust safeguards and audit trails are in place.